Giới thiệu
 Trí tuệ nhân tạo là tất cả về việc sử dụng máy móc để nâng cao cuộc sống và lối sống của con người bằng cách làm cho cuộc sống trần tục của họ trở nên thú vị và những công việc thừa trở nên đơn giản. AI không bao giờ được coi là một lực lượng thống trị mà là một lực lượng bổ sung hoạt động song song với con người để giải quyết những điều không tưởng và mở đường cho sự tiến hóa tập thể.
Trí tuệ nhân tạo là tất cả về việc sử dụng máy móc để nâng cao cuộc sống và lối sống của con người bằng cách làm cho cuộc sống trần tục của họ trở nên thú vị và những công việc thừa trở nên đơn giản. AI không bao giờ được coi là một lực lượng thống trị mà là một lực lượng bổ sung hoạt động song song với con người để giải quyết những điều không tưởng và mở đường cho sự tiến hóa tập thể.
Hiện tại, chúng tôi đang đi trên con đường đúng đắn với những đột phá đáng kể xảy ra trên khắp các ngành với sự trợ giúp của AI. Ví dụ: nếu bạn chăm sóc sức khỏe, các hệ thống AI đi kèm với các mô hình học máy đang giúp các chuyên gia hiểu rõ hơn về bệnh ung thư và đưa ra các phương pháp điều trị cho căn bệnh này. Rối loạn thần kinh và các mối quan tâm như PTSD đang được điều trị với sự trợ giúp của AI. Vắc xin đang được phát triển với tốc độ nhanh chóng nhờ vào các thử nghiệm và mô phỏng lâm sàng được hỗ trợ bởi AI.
Không chỉ chăm sóc sức khỏe, mọi ngành hoặc phân khúc mà AI tiếp xúc đều đang được cách mạng hóa. Các phương tiện tự lái, cửa hàng tiện lợi thông minh, thiết bị đeo được như FitBit và thậm chí cả camera trên điện thoại thông minh của chúng tôi đều có thể chụp những hình ảnh tốt hơn về khuôn mặt của chúng tôi với AI.
Nhờ những đổi mới đang diễn ra trong không gian AI, các công ty đang lấn sân sang lĩnh vực với nhiều trường hợp sử dụng và giải pháp khác nhau. Do đó, thị trường AI toàn cầu được dự đoán sẽ đạt giá trị thị trường khoảng 267 tỷ đô la vào cuối năm 2027. Bên cạnh đó, khoảng 37% doanh nghiệp hiện đã triển khai các giải pháp AI vào các quy trình và sản phẩm của họ.
Thú vị hơn, gần 77% sản phẩm và dịch vụ mà chúng ta sử dụng ngày nay được cung cấp bởi AI. Với khái niệm công nghệ đang gia tăng đáng kể trên khắp các ngành dọc, làm cách nào để các doanh nghiệp có thể làm được điều không thể với AI?

 Làm thế nào để các thiết bị đơn giản như một chiếc đồng hồ dự đoán chính xác các cơn đau tim ở người? Làm thế nào mà ô tô và ô tô luôn yêu cầu người lái xe lại đột nhiên ít lái xe hơn trên đường?
Làm thế nào để các thiết bị đơn giản như một chiếc đồng hồ dự đoán chính xác các cơn đau tim ở người? Làm thế nào mà ô tô và ô tô luôn yêu cầu người lái xe lại đột nhiên ít lái xe hơn trên đường?
Làm thế nào để chatbot khiến chúng ta tin rằng chúng ta đang nói chuyện với một người khác ở phía bên kia?
Nếu bạn quan sát câu trả lời cho mọi câu hỏi, nó chỉ tóm gọn ở một yếu tố - DỮ LIỆU. Dữ liệu nằm ở trung tâm của tất cả các hoạt động và quy trình dành riêng cho AI. Đó là dữ liệu giúp máy móc hiểu các khái niệm, xử lý đầu vào và đưa ra kết quả chính xác.
Tất cả các giải pháp AI chính hiện có đều là sản phẩm của một quá trình quan trọng mà chúng tôi gọi là thu thập dữ liệu hoặc thu thập dữ liệu hoặc dữ liệu đào tạo AI.
Hướng dẫn mở rộng này nhằm giúp bạn hiểu nó là gì và tại sao nó lại quan trọng.
Thu thập dữ liệu AI là gì?
Máy móc không có tâm trí của riêng chúng. Sự vắng mặt của khái niệm trừu tượng này khiến họ không có ý kiến, sự kiện và khả năng như lý luận, nhận thức và hơn thế nữa. Chúng chỉ là những chiếc hộp bất động hoặc những thiết bị chiếm không gian. Để biến chúng thành phương tiện mạnh mẽ, bạn cần các thuật toán và quan trọng hơn là dữ liệu.
 Các thuật toán được phát triển cần một cái gì đó để làm việc và xử lý và cái gì đó là dữ liệu có liên quan, theo ngữ cảnh và gần đây. Quá trình thu thập dữ liệu đó cho máy móc để phục vụ các mục đích đã định của chúng được gọi là thu thập dữ liệu AI.
Các thuật toán được phát triển cần một cái gì đó để làm việc và xử lý và cái gì đó là dữ liệu có liên quan, theo ngữ cảnh và gần đây. Quá trình thu thập dữ liệu đó cho máy móc để phục vụ các mục đích đã định của chúng được gọi là thu thập dữ liệu AI.
Mỗi sản phẩm hoặc giải pháp hỗ trợ AI mà chúng tôi sử dụng ngày nay và kết quả mà chúng mang lại đều bắt nguồn từ nhiều năm đào tạo, phát triển và tối ưu hóa. Từ các thiết bị cung cấp các tuyến đường điều hướng đến các hệ thống phức tạp dự đoán trước ngày hỏng hóc của thiết bị, mọi thực thể đều đã trải qua nhiều năm đào tạo về AI để có thể đưa ra kết quả chính xác.
Thu thập dữ liệu AI là bước sơ bộ trong quá trình phát triển AI mà ngay từ đầu sẽ xác định mức độ hiệu quả và hiệu quả của một hệ thống AI. Quá trình tìm nguồn cung cấp các bộ dữ liệu có liên quan từ vô số nguồn sẽ giúp các mô hình AI xử lý chi tiết tốt hơn và đưa ra các kết quả có ý nghĩa.




Cách thu thập dữ liệu cho Học máy?
 Đây là lúc mọi thứ bắt đầu trở nên phức tạp một chút. Ngay từ đầu, có vẻ như bạn đã có giải pháp cho một vấn đề trong thế giới thực, bạn biết AI sẽ là cách lý tưởng để giải quyết vấn đề đó và bạn đã phát triển các mô hình của mình. Nhưng bây giờ, bạn đang ở trong giai đoạn quan trọng, nơi bạn cần bắt đầu các quy trình đào tạo AI của mình. Bạn cần có nhiều dữ liệu đào tạo về AI để làm cho các mô hình của bạn học được các khái niệm và mang lại kết quả. Bạn cũng cần dữ liệu xác thực để kiểm tra kết quả và tối ưu hóa các thuật toán của mình.
Đây là lúc mọi thứ bắt đầu trở nên phức tạp một chút. Ngay từ đầu, có vẻ như bạn đã có giải pháp cho một vấn đề trong thế giới thực, bạn biết AI sẽ là cách lý tưởng để giải quyết vấn đề đó và bạn đã phát triển các mô hình của mình. Nhưng bây giờ, bạn đang ở trong giai đoạn quan trọng, nơi bạn cần bắt đầu các quy trình đào tạo AI của mình. Bạn cần có nhiều dữ liệu đào tạo về AI để làm cho các mô hình của bạn học được các khái niệm và mang lại kết quả. Bạn cũng cần dữ liệu xác thực để kiểm tra kết quả và tối ưu hóa các thuật toán của mình.
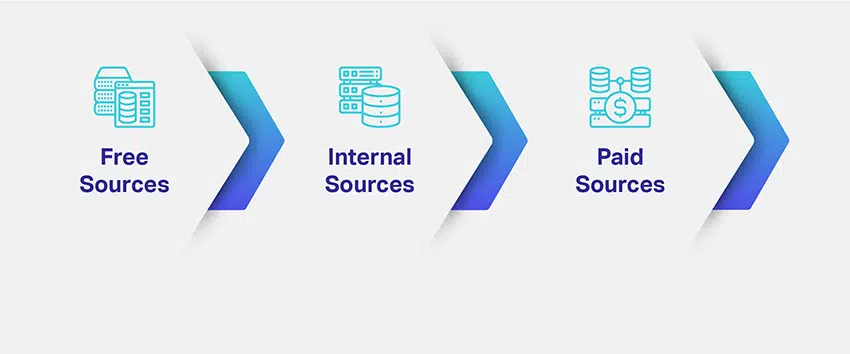
Vì vậy, làm thế nào để bạn nguồn dữ liệu của bạn? Bạn cần dữ liệu gì và bao nhiêu? Nhiều nguồn để tìm nạp dữ liệu có liên quan là gì?
Các công ty đánh giá thị trường ngách và mục đích của các mô hình ML của họ và vạch ra những cách tiềm năng để tìm nguồn tập dữ liệu có liên quan. Việc xác định kiểu dữ liệu cần thiết sẽ giải quyết được phần lớn mối quan tâm của bạn về nguồn cung cấp dữ liệu. Để cung cấp cho bạn ý tưởng tốt hơn, có các kênh, cách đi, nguồn hoặc phương tiện khác nhau để thu thập dữ liệu:
Dữ liệu xấu ảnh hưởng đến tham vọng AI của bạn như thế nào?
Chúng tôi đã liệt kê ra ba nguồn dữ liệu phổ biến nhất vì lý do bạn sẽ có ý tưởng về cách tiếp cận việc thu thập và tìm nguồn cung ứng dữ liệu. Tuy nhiên, tại thời điểm này, bạn cũng cần hiểu rằng quyết định của bạn luôn có thể quyết định số phận của giải pháp AI của bạn.
Tương tự như cách dữ liệu đào tạo AI chất lượng cao có thể giúp mô hình của bạn cung cấp kết quả chính xác và kịp thời, dữ liệu đào tạo không tốt cũng có thể phá vỡ mô hình AI của bạn, làm sai lệch kết quả, đưa ra sự sai lệch và gây ra những hậu quả không mong muốn khác.
Nhưng tại sao điều này lại xảy ra? Không phải bất kỳ dữ liệu nào được cho là để đào tạo và tối ưu hóa mô hình AI của bạn? Thành thật mà nói, không. Chúng ta hãy hiểu điều này hơn nữa.
Dữ liệu xấu - Nó là gì?
 Dữ liệu xấu là bất kỳ dữ liệu nào không liên quan, không chính xác, không đầy đủ hoặc thiên vị. Nhờ các chiến lược thu thập dữ liệu chưa được xác định rõ ràng, hầu hết các nhà khoa học dữ liệu và chuyên gia chú thích buộc phải làm việc trên dữ liệu xấu.
Dữ liệu xấu là bất kỳ dữ liệu nào không liên quan, không chính xác, không đầy đủ hoặc thiên vị. Nhờ các chiến lược thu thập dữ liệu chưa được xác định rõ ràng, hầu hết các nhà khoa học dữ liệu và chuyên gia chú thích buộc phải làm việc trên dữ liệu xấu.
Sự khác biệt giữa dữ liệu không có cấu trúc và dữ liệu xấu là thông tin chi tiết về dữ liệu phi cấu trúc ở khắp nơi. Nhưng về bản chất, chúng có thể hữu ích bất kể. Bằng cách dành thêm thời gian, các nhà khoa học dữ liệu vẫn có thể trích xuất thông tin liên quan từ các tập dữ liệu phi cấu trúc. Tuy nhiên, đó không phải là trường hợp của dữ liệu xấu. Các bộ dữ liệu này không chứa / giới hạn những hiểu biết hoặc thông tin có giá trị hoặc liên quan đến dự án AI của bạn hoặc mục đích đào tạo của nó.
Vì vậy, khi bạn lấy bộ dữ liệu của mình từ các nguồn miễn phí hoặc có các điểm tiếp xúc dữ liệu nội bộ được thiết lập lỏng lẻo, rất có thể bạn sẽ tải xuống hoặc tạo ra dữ liệu xấu. Khi các nhà khoa học của bạn làm việc trên dữ liệu xấu, bạn không chỉ lãng phí thời gian của con người mà còn thúc đẩy việc ra mắt sản phẩm của mình.
Nếu bạn vẫn chưa rõ về những dữ liệu xấu có thể ảnh hưởng đến tham vọng của bạn, đây là danh sách nhanh:
- Bạn dành vô số giờ để tìm nguồn cung cấp dữ liệu xấu và lãng phí hàng giờ, công sức và tiền bạc vào tài nguyên.
- Dữ liệu xấu có thể mang đến cho bạn những rắc rối pháp lý, nếu không được chú ý và có thể làm giảm hiệu quả của AI của bạn
. - Khi bạn đưa sản phẩm của mình được đào tạo trực tiếp về dữ liệu xấu, điều đó sẽ ảnh hưởng đến trải nghiệm người dùng
- Dữ liệu xấu có thể làm cho kết quả và suy luận bị sai lệch, điều này có thể gây ra phản ứng dữ dội hơn nữa.
Vì vậy, nếu bạn đang tự hỏi liệu có giải pháp nào cho vấn đề này hay không, thì thực sự là có.
Các nhà cung cấp dữ liệu đào tạo AI để giải cứu
 Một trong những giải pháp cơ bản là tìm đến nhà cung cấp dữ liệu (các nguồn trả phí). Các nhà cung cấp dữ liệu đào tạo AI đảm bảo những gì bạn nhận được là chính xác và có liên quan và bạn có các bộ dữ liệu được gửi cho bạn ở dạng có cấu trúc. Bạn không cần phải tham gia vào sự phức tạp của việc di chuyển từ cổng này sang cổng khác để tìm kiếm tập dữ liệu.
Một trong những giải pháp cơ bản là tìm đến nhà cung cấp dữ liệu (các nguồn trả phí). Các nhà cung cấp dữ liệu đào tạo AI đảm bảo những gì bạn nhận được là chính xác và có liên quan và bạn có các bộ dữ liệu được gửi cho bạn ở dạng có cấu trúc. Bạn không cần phải tham gia vào sự phức tạp của việc di chuyển từ cổng này sang cổng khác để tìm kiếm tập dữ liệu.
Tất cả những gì bạn phải làm là thu thập dữ liệu và đào tạo các mô hình AI của mình để hoàn thiện. Với điều đó đã nói, chúng tôi chắc chắn rằng câu hỏi tiếp theo của bạn là về chi phí liên quan đến việc cộng tác với các nhà cung cấp dữ liệu. Chúng tôi hiểu rằng một số bạn đã làm việc dựa trên kinh phí tinh thần và đó chính xác là nơi chúng tôi sẽ hướng tới tiếp theo.
Các yếu tố cần xem xét khi đưa ra Ngân sách hiệu quả cho Dự án Thu thập Dữ liệu của bạn
Đào tạo AI là một cách tiếp cận có hệ thống và đó là lý do tại sao lập ngân sách trở thành một phần không thể thiếu của nó. Các yếu tố như RoI, độ chính xác của kết quả, phương pháp đào tạo và hơn thế nữa cần được xem xét trước khi đầu tư một số tiền lớn vào phát triển AI. Rất nhiều nhà quản lý dự án hoặc chủ doanh nghiệp lúng túng trong giai đoạn này. Họ đưa ra những quyết định vội vàng dẫn đến những thay đổi không thể đảo ngược trong quá trình phát triển sản phẩm của mình, cuối cùng buộc họ phải chi tiêu nhiều hơn.
Tuy nhiên, phần này sẽ cung cấp cho bạn những hiểu biết đúng đắn. Khi bạn đang tính toán ngân sách cho việc đào tạo AI, có ba điều hoặc yếu tố không thể tránh khỏi.

Hãy xem xét từng chi tiết.
Khối lượng dữ liệu bạn cần
Chúng tôi đã nói tất cả rằng hiệu quả và độ chính xác của mô hình AI của bạn phụ thuộc vào mức độ nó được đào tạo. Điều này có nghĩa là khối lượng bộ dữ liệu càng nhiều thì việc học càng nhiều. Nhưng điều này rất mơ hồ. Để đưa ra một con số cho khái niệm này, Dimensional Research đã công bố một báo cáo tiết lộ rằng các doanh nghiệp cần tối thiểu 100,000 bộ dữ liệu mẫu để đào tạo các mô hình AI của họ.
Với 100,000 bộ dữ liệu, chúng tôi có nghĩa là 100,000 bộ dữ liệu chất lượng và có liên quan. Các tập dữ liệu này phải có tất cả các thuộc tính, chú thích và thông tin chi tiết cần thiết cho các thuật toán và mô hình học máy của bạn để xử lý thông tin và thực thi các tác vụ dự kiến.
Với đây là quy tắc chung, hãy hiểu thêm rằng khối lượng dữ liệu bạn cần cũng phụ thuộc vào một yếu tố phức tạp khác là trường hợp sử dụng của doanh nghiệp bạn. Những gì bạn định làm với sản phẩm hoặc giải pháp của mình cũng quyết định lượng dữ liệu bạn cần. Ví dụ: một doanh nghiệp xây dựng một công cụ đề xuất sẽ có các yêu cầu về khối lượng dữ liệu khác với một công ty đang xây dựng một chatbot.
Chiến lược định giá dữ liệu
Khi bạn hoàn tất việc hoàn thành lượng dữ liệu thực sự cần, tiếp theo bạn cần làm việc với chiến lược định giá dữ liệu. Điều này, nói một cách đơn giản, có nghĩa là cách bạn sẽ trả tiền cho các tập dữ liệu mà bạn mua hoặc tạo ra.
Nói chung, đây là các chiến lược giá thông thường được áp dụng trên thị trường:
| Loại dữ liệu | Chiến lược giá |
|---|---|
| Định giá cho mỗi tệp hình ảnh đơn lẻ | |
| Định giá trên giây, phút, một giờ hoặc khung hình riêng lẻ | |
| Định giá mỗi giây, một phút hoặc giờ | |
| Định giá cho mỗi từ hoặc câu |
Nhưng đợi đã. Đây một lần nữa là một quy tắc ngón tay cái. Chi phí thực tế của việc mua sắm tập dữ liệu cũng phụ thuộc vào các yếu tố như:
- Phân khúc thị trường, nhân khẩu học hoặc địa lý duy nhất mà từ đó tập dữ liệu phải được lấy ra
- Sự phức tạp của trường hợp sử dụng của bạn
- Bạn cần bao nhiêu dữ liệu?
- Thời gian của bạn để tiếp thị
- Mọi yêu cầu phù hợp và hơn thế nữa
Nếu bạn quan sát, bạn sẽ biết rằng chi phí để có được số lượng lớn hình ảnh cho dự án AI của bạn có thể ít hơn nhưng nếu bạn có quá nhiều thông số kỹ thuật, giá có thể tăng lên.
Các chiến lược tìm nguồn cung ứng của bạn
Điều này là khó khăn. Như bạn đã thấy, có nhiều cách khác nhau để tạo hoặc nguồn dữ liệu cho các mô hình AI của bạn. Theo lẽ thường, các tài nguyên miễn phí là tốt nhất vì bạn có thể tải xuống miễn phí khối lượng bộ dữ liệu cần thiết mà không có bất kỳ biến chứng nào.
Ngay bây giờ, có vẻ như các nguồn trả phí quá đắt. Nhưng đây là nơi mà một lớp phức tạp được thêm vào. Khi bạn tìm nguồn cung cấp bộ dữ liệu từ các tài nguyên miễn phí, bạn đang dành thêm một lượng thời gian và công sức để làm sạch bộ dữ liệu của mình, biên dịch chúng thành định dạng dành riêng cho doanh nghiệp của bạn và sau đó chú thích chúng riêng lẻ. Bạn đang phải chịu chi phí hoạt động trong quá trình này.
Với các nguồn trả phí, việc thanh toán là một lần và bạn cũng nhận được bộ dữ liệu sẵn sàng cho máy tại thời điểm bạn yêu cầu. Hiệu quả chi phí là rất chủ quan ở đây. Nếu bạn cảm thấy mình có đủ khả năng để dành thời gian cho việc chú thích các tập dữ liệu miễn phí, bạn có thể lập ngân sách cho phù hợp. Và nếu bạn tin rằng sự cạnh tranh của bạn rất khốc liệt và với thời gian tiếp thị hạn chế, bạn có thể tạo ra hiệu ứng gợn sóng trên thị trường, bạn nên ưu tiên các nguồn trả phí.
Lập ngân sách là tất cả về việc chia nhỏ các chi tiết cụ thể và xác định rõ ràng từng phần. Ba yếu tố này sẽ phục vụ bạn như một lộ trình cho quá trình lập ngân sách đào tạo AI của bạn trong tương lai.
Bạn có đang tiết kiệm chi phí với Dịch vụ thu thập dữ liệu nội bộ không?
 Trong khi lập ngân sách, chúng tôi đã khám phá cách các tài nguyên miễn phí buộc bạn phải chi tiêu nhiều hơn trong thời gian dài. Tại thời điểm đó, bạn sẽ tự động thắc mắc về hiệu quả chi phí của quá trình thu thập dữ liệu nội bộ.
Trong khi lập ngân sách, chúng tôi đã khám phá cách các tài nguyên miễn phí buộc bạn phải chi tiêu nhiều hơn trong thời gian dài. Tại thời điểm đó, bạn sẽ tự động thắc mắc về hiệu quả chi phí của quá trình thu thập dữ liệu nội bộ.
Chúng tôi biết rằng bạn vẫn còn do dự về các nguồn trả phí và đó là lý do tại sao phần này sẽ xóa bỏ sự hoài nghi của bạn về nó và làm sáng tỏ các chi phí ẩn liên quan đến việc tạo dữ liệu nội bộ.
Thu thập dữ liệu nội bộ có đắt không?
Vâng, nó là vậy!
Bây giờ, đây là một câu trả lời phức tạp. Chi phí là bất cứ thứ gì bạn chi tiêu. Trong khi thảo luận về các tài nguyên miễn phí, chúng tôi tiết lộ rằng bạn đã tiêu tốn tiền bạc, thời gian và công sức cho quá trình này. Điều này cũng áp dụng cho việc thu thập dữ liệu nội bộ.
 Vì thực tế là bạn có các điểm tiếp xúc hoặc kênh dữ liệu được xác định tùy chỉnh, điều đó không có nghĩa là bạn sẽ có bộ dữ liệu sẵn sàng cho máy móc đến cuối cùng. Dữ liệu bạn tạo chủ yếu vẫn là dữ liệu thô và không có cấu trúc. Bạn có thể có tất cả dữ liệu bạn cần ở một nơi nhưng những gì dữ liệu chứa sẽ ở khắp nơi.
Vì thực tế là bạn có các điểm tiếp xúc hoặc kênh dữ liệu được xác định tùy chỉnh, điều đó không có nghĩa là bạn sẽ có bộ dữ liệu sẵn sàng cho máy móc đến cuối cùng. Dữ liệu bạn tạo chủ yếu vẫn là dữ liệu thô và không có cấu trúc. Bạn có thể có tất cả dữ liệu bạn cần ở một nơi nhưng những gì dữ liệu chứa sẽ ở khắp nơi.
Cuối cùng, bạn sẽ phải chi trả cho việc trả lương cho nhân viên, nhà khoa học dữ liệu, người chú thích, chuyên gia đảm bảo chất lượng và hơn thế nữa. Bạn cũng sẽ chi tiêu cho các đăng ký cho các công cụ chú thích và
bảo trì CMS, CRM và các chi phí cơ sở hạ tầng khác.
Bên cạnh đó, các tập dữ liệu nhất định có mối quan tâm về độ lệch và độ chính xác, mà bạn cần phải sắp xếp chúng theo cách thủ công. Và nếu bạn gặp vấn đề về tiêu hao trong nhóm dữ liệu đào tạo AI của mình, bạn sẽ phải chi tiêu vào việc tuyển dụng thành viên mới, định hướng họ theo quy trình của bạn, đào tạo họ sử dụng các công cụ của bạn và hơn thế nữa.
Cuối cùng bạn sẽ chi tiêu nhiều hơn những gì cuối cùng bạn sẽ kiếm được trong thời gian dài. Ngoài ra còn có chi phí chú thích. Tại bất kỳ thời điểm nào, tổng chi phí phát sinh để xử lý dữ liệu nội bộ là:
Chi phí phát sinh = Số lượng chú thích * Giá mỗi chú thích + Chi phí nền tảng
Nếu lịch đào tạo AI của bạn được lên lịch trong nhiều tháng, hãy tưởng tượng các khoản chi phí bạn sẽ phải chịu liên tục. Vì vậy, đây có phải là giải pháp lý tưởng cho các mối quan tâm về thu thập dữ liệu hay có bất kỳ giải pháp thay thế nào không?
Cách chọn Công ty thu thập dữ liệu AI phù hợp
Chọn một công ty thu thập dữ liệu AI không phức tạp hoặc tốn thời gian như thu thập dữ liệu từ các tài nguyên miễn phí. Chỉ có một số yếu tố đơn giản bạn cần xem xét và sau đó bắt tay để hợp tác.
Khi bạn bắt đầu tìm kiếm nhà cung cấp dữ liệu, chúng tôi giả định rằng bạn đã theo dõi và cân nhắc bất cứ điều gì chúng tôi đã thảo luận cho đến nay. Tuy nhiên, đây là một bản tóm tắt nhanh:
- Bạn có một trường hợp sử dụng được xác định rõ ràng trong tâm trí
- Phân khúc thị trường và yêu cầu dữ liệu của bạn được thiết lập rõ ràng
- Ngân sách của bạn đang đúng
- Và bạn có ý tưởng về khối lượng dữ liệu bạn cần
Với những mục này được đánh dấu chọn, hãy hiểu cách bạn có thể tìm kiếm một nhà cung cấp dịch vụ dữ liệu đào tạo lý tưởng.