
Hệ thống Nhận dạng giọng nói tự động và các trợ lý ảo như Siri, Alexa và Cortana đã trở thành những phần phổ biến trong cuộc sống của chúng ta. Sự phụ thuộc của chúng ta vào chúng đang tăng lên đáng kể khi chúng ngày càng thông minh hơn. Từ việc bật đèn đến thực hiện cuộc gọi đến thay đổi kênh truyền hình, chúng tôi tận dụng các công nghệ thông minh này để hoàn thành các công việc thông thường.
Tuy nhiên, bạn có bao giờ tự hỏi các hệ thống nhận dạng giọng nói này hoạt động như thế nào không?
Chà, blog này sẽ hướng dẫn bạn một số nguyên tắc cơ bản về Nhận dạng giọng nói tự động. Ngoài ra, chúng ta sẽ khám phá cách hoạt động của nó và cách các trợ lý ảo chức năng như Siri được xây dựng.
Nhận dạng giọng nói tự động là gì?
Nhận dạng giọng nói tự động (ASR) là phần mềm cho phép hệ thống máy tính chuyển đổi giọng nói của con người thành văn bản, sử dụng nhiều thuật toán máy học và trí tuệ nhân tạo.
Sau khi chuyển đổi và phân tích lệnh đã cho, máy tính sẽ phản hồi với một đầu ra thích hợp cho người dùng. ASR được giới thiệu lần đầu tiên vào năm 1962, và kể từ đó, nó đã liên tục cải tiến hoạt động của mình và nhận được sự chú ý lớn nhờ các ứng dụng phổ biến như Alexa và Siri.
Quy trình thu thập lời nói để đào tạo mô hình ASR là gì?
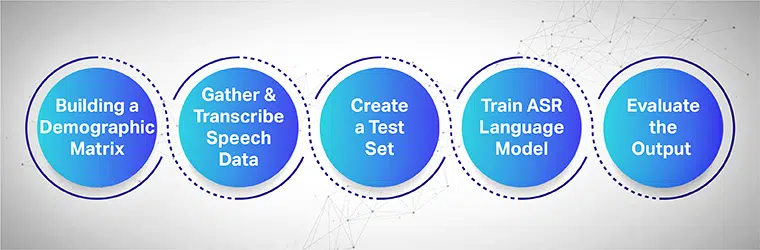
Bộ sưu tập lời nói nhằm mục đích thu thập một số bản ghi âm mẫu từ nhiều khu vực được sử dụng để cung cấp và đào tạo các mô hình ASR. Hệ thống ASR mang lại hiệu quả cao nhất khi tập dữ liệu lớn về giọng nói và âm thanh được thu thập và cung cấp cho hệ thống của nó.
Để hoạt động trơn tru, tập dữ liệu giọng nói được thu thập phải chứa tất cả thông tin nhân khẩu học, ngôn ngữ, trọng âm và phương ngữ mục tiêu. Quy trình sau đây trình bày cách đào tạo mô hình học máy theo nhiều bước:
Bắt đầu bằng cách xây dựng ma trận nhân khẩu học
Trước hết thu thập dữ liệu cho các nhân khẩu học khác nhau như vị trí, giới tính, ngôn ngữ, độ tuổi và giọng. Ngoài ra, hãy đảm bảo ghi lại nhiều loại tiếng ồn khác nhau trong môi trường như tiếng ồn đường phố, tiếng ồn phòng chờ, tiếng ồn văn phòng công cộng, v.v.
Thu thập và phiên âm dữ liệu giọng nói
Bước tiếp theo là thu thập các mẫu âm thanh và giọng nói của con người dựa trên các vị trí địa lý khác nhau để đào tạo mô hình ASR của bạn. Đây là một bước quan trọng và đòi hỏi các chuyên gia về con người phải thực hiện các cách phát âm dài và ngắn của các từ để có được cảm giác chân thực của câu và lặp lại các câu giống nhau bằng các giọng và phương ngữ khác nhau.
Tạo một bộ thử nghiệm riêng biệt
Khi bạn đã thu thập được văn bản đã phiên âm, bước tiếp theo là ghép nối văn bản đó với dữ liệu âm thanh tương ứng. Sau đó, phân đoạn dữ liệu xa hơn và bao gồm một câu lệnh từ chúng. Giờ đây, từ các cặp dữ liệu được phân đoạn, bạn có thể lấy dữ liệu ngẫu nhiên từ một tập hợp để thử nghiệm thêm.
Đào tạo mô hình ngôn ngữ ASR của bạn
Bộ dữ liệu của bạn càng có nhiều thông tin, mô hình được đào tạo bởi AI của bạn sẽ hoạt động tốt hơn. Do đó, hãy tạo nhiều biến thể của văn bản và bài phát biểu mà bạn đã ghi lại trước đó. Diễn giải các câu giống nhau bằng cách sử dụng các ký hiệu giọng nói khác nhau.
Đánh giá đầu ra và cuối cùng, lặp lại
Cuối cùng, đo lường đầu ra của mô hình ASR của bạn để khắc phục hiệu suất của nó. Thử nghiệm mô hình dựa trên một tập hợp thử nghiệm để xác định hiệu quả của nó. Một cách phù hợp, hãy tham gia mô hình ASR của bạn vào một vòng phản hồi để tạo ra kết quả đầu ra mong muốn và khắc phục bất kỳ khoảng trống nào.
[Cũng đọc: Tổng quan Toàn diện về Nhận dạng Giọng nói Tự động]

Các trường hợp sử dụng khác nhau của nhận dạng giọng nói là gì?
Công nghệ nhận dạng giọng nói đang rất thịnh hành trong nhiều ngành công nghiệp ngày nay. Một số ngành sử dụng công nghệ to lớn này như sau:
 Ngành công nghiệp thực phẩm: Những gã khổng lồ về thực phẩm như Wendy's và McDonald's được thiết lập để nâng cao trải nghiệm khách hàng của họ bằng cách sử dụng ASR. Tại nhiều cửa hàng của họ, họ đã triển khai các mô hình ASR đầy đủ chức năng để nhận đơn đặt hàng, và tiếp tục chuyển chúng đến bộ phận nấu ăn để làm cho đơn đặt hàng của khách hàng đã sẵn sàng.
Ngành công nghiệp thực phẩm: Những gã khổng lồ về thực phẩm như Wendy's và McDonald's được thiết lập để nâng cao trải nghiệm khách hàng của họ bằng cách sử dụng ASR. Tại nhiều cửa hàng của họ, họ đã triển khai các mô hình ASR đầy đủ chức năng để nhận đơn đặt hàng, và tiếp tục chuyển chúng đến bộ phận nấu ăn để làm cho đơn đặt hàng của khách hàng đã sẵn sàng.- Viễn thông: Vodafone là một trong những nhà cung cấp dịch vụ viễn thông lớn nhất trên thế giới. Nó đã thiết kế các dịch vụ chăm sóc khách hàng và chuyển tiếp điện thoại tận dụng các mô hình ASR để hướng dẫn bạn giải quyết các truy vấn khác nhau và định tuyến lại các cuộc gọi của bạn đến các bộ phận liên quan.
- Du lịch và Vận chuyển: Google Android Auto hoặc Apple CarPlay đã trở nên phổ biến. Hầu hết mọi người sử dụng chúng để kích hoạt hệ thống định vị, gửi tin nhắn hoặc chuyển đổi danh sách phát nhạc. Tuy nhiên, với những tiến bộ về công nghệ, các hệ thống như vậy ngày càng trở nên hoàn thiện hơn.
BMW Intelligent Personal Assistant ra mắt trên BMW 3 Series thông minh hơn nhiều so với trợ lý giọng nói thông thường. Nó có thể cho phép người lái xe tìm kiếm thông tin liên quan đến xe hơi và vận hành xe bằng lệnh thoại. - Truyền thông và Giải trí: Ngành công nghiệp truyền thông cũng sử dụng ASR trong nhiều dự án của mình. Youtube đã ra mắt một trợ lý dựa trên AI giúp tạo phụ đề tự động trực tiếp. Khi bạn nói trên màn hình, trợ lý sẽ cung cấp phụ đề để giúp một nhóm lớn người dùng Youtube có thể truy cập video.
 Ngành công nghiệp thực phẩm: Những gã khổng lồ về thực phẩm như Wendy's và McDonald's được thiết lập để nâng cao trải nghiệm khách hàng của họ bằng cách sử dụng ASR. Tại nhiều cửa hàng của họ, họ đã triển khai các mô hình ASR đầy đủ chức năng để nhận đơn đặt hàng, và tiếp tục chuyển chúng đến bộ phận nấu ăn để làm cho đơn đặt hàng của khách hàng đã sẵn sàng.
Ngành công nghiệp thực phẩm: Những gã khổng lồ về thực phẩm như Wendy's và McDonald's được thiết lập để nâng cao trải nghiệm khách hàng của họ bằng cách sử dụng ASR. Tại nhiều cửa hàng của họ, họ đã triển khai các mô hình ASR đầy đủ chức năng để nhận đơn đặt hàng, và tiếp tục chuyển chúng đến bộ phận nấu ăn để làm cho đơn đặt hàng của khách hàng đã sẵn sàng. Viễn thông: Vodafone là một trong những nhà cung cấp dịch vụ viễn thông lớn nhất trên thế giới. Nó đã thiết kế các dịch vụ chăm sóc khách hàng và chuyển tiếp điện thoại tận dụng các mô hình ASR để hướng dẫn bạn giải quyết các truy vấn khác nhau và định tuyến lại các cuộc gọi của bạn đến các bộ phận liên quan.
Viễn thông: Vodafone là một trong những nhà cung cấp dịch vụ viễn thông lớn nhất trên thế giới. Nó đã thiết kế các dịch vụ chăm sóc khách hàng và chuyển tiếp điện thoại tận dụng các mô hình ASR để hướng dẫn bạn giải quyết các truy vấn khác nhau và định tuyến lại các cuộc gọi của bạn đến các bộ phận liên quan. Du lịch và Vận chuyển: Google Android Auto hoặc Apple CarPlay đã trở nên phổ biến. Hầu hết mọi người sử dụng chúng để kích hoạt hệ thống định vị, gửi tin nhắn hoặc chuyển đổi danh sách phát nhạc. Tuy nhiên, với những tiến bộ về công nghệ, các hệ thống như vậy ngày càng trở nên hoàn thiện hơn.
Du lịch và Vận chuyển: Google Android Auto hoặc Apple CarPlay đã trở nên phổ biến. Hầu hết mọi người sử dụng chúng để kích hoạt hệ thống định vị, gửi tin nhắn hoặc chuyển đổi danh sách phát nhạc. Tuy nhiên, với những tiến bộ về công nghệ, các hệ thống như vậy ngày càng trở nên hoàn thiện hơn. Truyền thông và Giải trí: Ngành công nghiệp truyền thông cũng sử dụng ASR trong nhiều dự án của mình. Youtube đã ra mắt một trợ lý dựa trên AI giúp tạo phụ đề tự động trực tiếp. Khi bạn nói trên màn hình, trợ lý sẽ cung cấp phụ đề để giúp một nhóm lớn người dùng Youtube có thể truy cập video.
Truyền thông và Giải trí: Ngành công nghiệp truyền thông cũng sử dụng ASR trong nhiều dự án của mình. Youtube đã ra mắt một trợ lý dựa trên AI giúp tạo phụ đề tự động trực tiếp. Khi bạn nói trên màn hình, trợ lý sẽ cung cấp phụ đề để giúp một nhóm lớn người dùng Youtube có thể truy cập video.
[Cũng đọc: Công nghệ chuyển giọng nói thành văn bản là gì và nó hoạt động như thế nào]
Shaip có thể giúp gì?
Shaip là một trong những dịch vụ đào tạo AI hàng đầu có chuyên môn trong nhiều lĩnh vực AI và ML. Họ có thể giúp bạn xây dựng tập dữ liệu của riêng bạn có thể được sử dụng cho các ứng dụng và dự án khác nhau.
Một số dịch vụ do Shaip cung cấp là:
- Nhận dạng giọng nói tự động (ASR)
- Bộ sưu tập lời nói theo kịch bản
- Sự chuyển giao
- Bộ sưu tập Bài phát biểu tự phát
- Bộ sưu tập Utterance / Lời đánh thức,
- Chuyển văn bản thành giọng nói (TTS)
Bạn có thể tận dụng các dịch vụ này để có được kết quả tốt nhất cho các dự án dựa trên AI của mình. Biết thêm về các dịch vụ này bằng cách liên hệ với nhóm chuyên gia của chúng tôi ngay hôm nay!


