
Nhận dạng giọng nói tự động (ASR) đã đi một chặng đường dài. Mặc dù nó đã được phát minh từ lâu nhưng nó hầu như không được ai sử dụng. Tuy nhiên, thời gian và công nghệ hiện nay đã thay đổi đáng kể. Phiên âm âm thanh đã phát triển đáng kể.
Các công nghệ như AI (Trí tuệ nhân tạo) đã hỗ trợ quá trình dịch âm thanh sang văn bản để có kết quả nhanh chóng và chính xác. Do đó, các ứng dụng của nó trong thế giới thực cũng tăng lên, với một số ứng dụng phổ biến như Tik Tok, Spotify và Zoom có thể nhúng quy trình vào ứng dụng di động của họ.
Vì vậy, hãy cùng chúng tôi khám phá ASR và khám phá lý do tại sao nó là một trong những công nghệ phổ biến nhất vào năm 2022.
Lời nói thành văn bản là gì?
Nói thành văn bản là một công nghệ được nâng cao bởi AI giúp chuyển lời nói của con người từ dạng tương tự sang dạng kỹ thuật số. Hơn nữa, dạng kỹ thuật số của dữ liệu đã thu thập được chuyển sang định dạng văn bản.
Nói thành văn bản thường bị nhầm lẫn với nhận dạng giọng nói, điều này hoàn toàn khác với phương pháp này. Trong nhận dạng giọng nói, trọng tâm là xác định các mẫu giọng nói của mọi người, trong khi trong phương pháp này, hệ thống cố gắng xác định các từ đang được nói.
Tên thông dụng của lời nói thành văn bản
Công nghệ nhận dạng giọng nói tiên tiến này cũng phổ biến và được gọi bằng các tên:
- Nhận dạng giọng nói tự động (ASR)
- Nhận dạng giọng nói
- Nhận dạng giọng nói máy tính
- Phiên âm
- Đọc màn hình
Hiểu hoạt động của tính năng nhận dạng giọng nói tự động
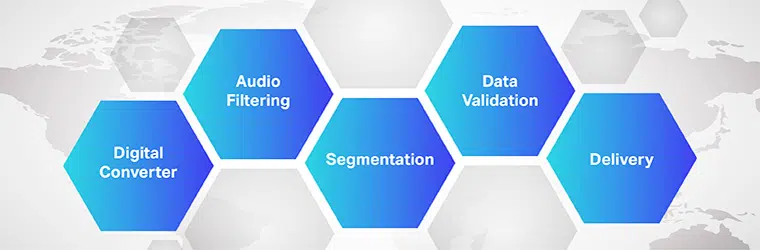
Hoạt động của phần mềm dịch từ âm thanh sang văn bản rất phức tạp và bao gồm việc thực hiện nhiều bước. Như chúng ta đã biết, giọng nói thành văn bản là một phần mềm độc quyền được thiết kế để chuyển đổi các tệp âm thanh thành một định dạng văn bản có thể chỉnh sửa; nó thực hiện điều đó bằng cách tận dụng nhận dạng giọng nói.
Quy trình xét duyệt
- Ban đầu, bằng cách sử dụng bộ chuyển đổi tương tự sang kỹ thuật số, một chương trình máy tính áp dụng các thuật toán ngôn ngữ vào dữ liệu được cung cấp để phân biệt các rung động từ các tín hiệu thính giác.
- Tiếp theo, các âm thanh liên quan được lọc bằng cách đo sóng âm thanh.
- Hơn nữa, các âm thanh được phân phối / phân đoạn thành phần trăm hoặc phần nghìn giây và khớp với âm vị (Một đơn vị âm thanh có thể đo lường để phân biệt từ này với từ khác).
- Các âm vị được tiếp tục chạy qua một mô hình toán học để so sánh dữ liệu hiện có với các từ, câu và cụm từ nổi tiếng.
- Đầu ra ở dạng văn bản hoặc tệp âm thanh dựa trên máy tính.
[Cũng đọc: Tổng quan Toàn diện về Nhận dạng Giọng nói Tự động]

Công dụng của lời nói thành văn bản là gì?
Có nhiều cách sử dụng phần mềm nhận dạng giọng nói tự động, chẳng hạn như
- Tìm kiếm Nội dung: Hầu hết chúng ta đã chuyển từ việc gõ chữ trên điện thoại sang cách nhấn nút để phần mềm nhận dạng giọng nói của chúng ta và đưa ra kết quả mong muốn.
- Dịch vụ khách hàng: Chatbots và trợ lý AI có thể hướng dẫn khách hàng qua một vài bước ban đầu của quy trình đã trở nên phổ biến.
- Phụ đề chi tiết theo thời gian thực: Với việc gia tăng khả năng tiếp cận nội dung trên toàn cầu, phụ đề chi tiết trong thời gian thực đã trở thành một thị trường nổi bật và quan trọng, thúc đẩy ASR tiếp tục được sử dụng.
- Tài liệu Điện tử: Một số bộ phận quản trị đã bắt đầu sử dụng ASR để thực hiện các mục đích tài liệu, phục vụ cho tốc độ và hiệu quả tốt hơn.
Những Thách thức Chính đối với Nhận dạng Giọng nói là gì?
Chú thích âm thanh vẫn chưa đạt đến đỉnh cao của sự phát triển. Vẫn còn nhiều thách thức mà các kỹ sư đang cố gắng đối phó để làm cho hệ thống hoạt động hiệu quả, chẳng hạn như
- Có được quyền kiểm soát đối với trọng âm và phương ngữ.
- Hiểu ngữ cảnh của các câu nói.
- Tách các tạp âm nền để khuếch đại chất lượng đầu vào.
- Chuyển mã sang các ngôn ngữ khác nhau để xử lý hiệu quả.
- Phân tích các dấu hiệu hình ảnh được sử dụng trong bài phát biểu trong trường hợp tệp video.
Phiên âm âm thanh và phát triển AI chuyển giọng nói thành văn bản
Thách thức lớn nhất với phần mềm Nhận dạng giọng nói tự động là tạo ra đầu ra chính xác 100%. Vì dữ liệu thô là dữ liệu động và không thể áp dụng một thuật toán duy nhất, nên dữ liệu được chú thích để đào tạo AI hiểu nó trong ngữ cảnh phù hợp.
Để thực hiện quá trình này, các nhiệm vụ cụ thể phải được thực hiện, chẳng hạn như:
 Nhận dạng đối tượng được đặt tên (NER): NER là quá trình xác định và phân đoạn các thực thể được đặt tên khác nhau thành các loại cụ thể.
Nhận dạng đối tượng được đặt tên (NER): NER là quá trình xác định và phân đoạn các thực thể được đặt tên khác nhau thành các loại cụ thể.- Phân tích tình cảm & chủ đề: Phần mềm sử dụng nhiều thuật toán tiến hành phân tích cảm tính của dữ liệu được cung cấp để đưa ra kết quả không có lỗi.
 Nhận dạng đối tượng được đặt tên (NER):
Nhận dạng đối tượng được đặt tên (NER): - Phân tích ý định & hội thoại: Phát hiện ý định nhằm mục đích đào tạo AI để nhận ra ý định của người nói. Nó chủ yếu được sử dụng để tạo các chatbot do AI hỗ trợ.
Kết luận
Công nghệ chuyển giọng nói thành văn bản đang ở giai đoạn tuyệt vời vào lúc này. Với nhiều thiết bị kỹ thuật số tích hợp trợ lý điều khiển và tìm kiếm bằng giọng nói vào ứng dụng của họ, nhu cầu về phiên âm âm thanh sẽ tăng lên. Nếu bạn muốn thêm tính năng ấn tượng này vào ứng dụng của mình, hãy liên hệ với các chuyên gia thu thập dữ liệu giọng nói của Shaip để biết đầy đủ chi tiết.


