
Trí tuệ nhân tạo thúc đẩy các tương tác giống như con người với các hệ thống máy tính, trong khi Học máy cho phép những máy này học cách bắt chước trí thông minh của con người thông qua mọi tương tác. Nhưng điều gì cung cấp năng lượng cho các công cụ ML và AI tiên tiến này? Chú thích dữ liệu.
Dữ liệu là nguyên liệu thô cung cấp năng lượng cho các thuật toán ML – bạn sử dụng càng nhiều dữ liệu, sản phẩm AI sẽ càng tốt hơn. Mặc dù điều cực kỳ quan trọng là có quyền truy cập vào số lượng lớn dữ liệu, nhưng điều quan trọng không kém là đảm bảo chúng được chú thích chính xác để mang lại kết quả khả thi. Chú thích dữ liệu là sức mạnh dữ liệu đằng sau hiệu suất thuật toán ML tiên tiến, đáng tin cậy và chính xác.
Vai trò của chú thích dữ liệu trong đào tạo AI
Chú thích dữ liệu đóng một vai trò quan trọng trong đào tạo ML và thành công chung của các dự án AI. Nó giúp xác định các hình ảnh, dữ liệu, mục tiêu và video cụ thể, đồng thời gắn nhãn cho chúng để giúp máy dễ dàng xác định các mẫu và phân loại dữ liệu hơn. Đó là một nhiệm vụ do con người thực hiện nhằm huấn luyện mô hình ML để đưa ra các dự đoán chính xác.
Nếu chú thích dữ liệu không được thực hiện chính xác, thuật toán ML không thể dễ dàng liên kết các thuộc tính với các đối tượng.
Tầm quan trọng của dữ liệu đào tạo được chú thích cho các hệ thống AI
Chú thích dữ liệu cho phép các mô hình ML hoạt động chính xác. Có một mối liên hệ không thể chối cãi giữa độ chính xác và độ chính xác của chú thích dữ liệu và sự thành công của dự án AI.
Giá trị thị trường AI toàn cầu, ước tính là 119 tỷ USD vào năm 2022, được dự đoán sẽ đạt $ 1,597 tỷ bởi 2030, tăng trưởng với tốc độ CAGR là 38% trong giai đoạn này. Mặc dù toàn bộ dự án AI trải qua một số bước quan trọng, nhưng giai đoạn chú thích dữ liệu là nơi dự án của bạn ở giai đoạn quan trọng nhất.
Thu thập dữ liệu vì lợi ích của dữ liệu sẽ không giúp ích nhiều cho dự án của bạn. Bạn cần số lượng lớn dữ liệu có liên quan, chất lượng cao để triển khai thành công dự án AI của mình. Khoảng 80% thời gian của bạn trong quá trình phát triển dự án ML được dành cho các nhiệm vụ liên quan đến dữ liệu, chẳng hạn như ghi nhãn, xóa, tổng hợp, xác định, bổ sung và chú thích.
Chú thích dữ liệu là một lĩnh vực mà con người có lợi thế hơn máy tính vì chúng ta có khả năng bẩm sinh để giải mã ý định, vượt qua sự mơ hồ và phân loại thông tin không chắc chắn.
Tại sao chú thích dữ liệu lại quan trọng?
Giá trị và độ tin cậy của giải pháp trí tuệ nhân tạo của bạn phụ thuộc phần lớn vào chất lượng dữ liệu đầu vào được sử dụng để đào tạo mô hình.
Máy không thể xử lý hình ảnh như chúng ta; họ cần được đào tạo để nhận ra các mẫu thông qua đào tạo. Vì các mô hình máy học phục vụ cho nhiều ứng dụng – các giải pháp quan trọng như chăm sóc sức khỏe và xe tự lái – trong đó bất kỳ lỗi nào trong chú thích dữ liệu đều có thể gây ra hậu quả nguy hiểm.
Chú thích dữ liệu đảm bảo rằng giải pháp AI của bạn hoạt động hết công suất. Đào tạo một mô hình ML để diễn giải chính xác môi trường của nó thông qua các mẫu và mối tương quan, đưa ra dự đoán và thực hiện hành động cần thiết yêu cầu được phân loại và chú thích cao dữ liệu đào tạo. Chú thích hiển thị cho mô hình ML dự đoán bắt buộc bằng cách gắn thẻ, sao chép và gắn nhãn các tính năng quan trọng trong tập dữ liệu.
Học có giám sát
Trước khi chúng tôi tìm hiểu sâu hơn về chú thích dữ liệu, hãy làm sáng tỏ chú thích dữ liệu thông qua học tập có giám sát và không giám sát.
Một danh mục con của machine learning có giám sát machine learning biểu thị quá trình đào tạo mô hình AI với sự trợ giúp của tập dữ liệu được gắn nhãn rõ ràng. Trong phương pháp học có giám sát, một số dữ liệu đã được gắn thẻ và chú thích chính xác. Mô hình ML, khi tiếp xúc với dữ liệu mới, sử dụng dữ liệu đào tạo để đưa ra dự đoán chính xác dựa trên dữ liệu được gắn nhãn.
Ví dụ, người mẫu ML được đào tạo trên một tủ đầy đủ các loại quần áo khác nhau. Bước đầu tiên trong quá trình huấn luyện sẽ là huấn luyện người mẫu với các loại quần áo khác nhau bằng cách sử dụng các đặc điểm và thuộc tính của từng loại vải. Sau khi đào tạo, máy sẽ có thể xác định các mảnh quần áo riêng biệt bằng cách áp dụng kiến thức hoặc đào tạo trước đó. Học có giám sát có thể được phân loại thành phân loại (dựa trên danh mục) và hồi quy (dựa trên giá trị thực).
Cách chú thích dữ liệu ảnh hưởng đến hiệu suất của các hệ thống AI
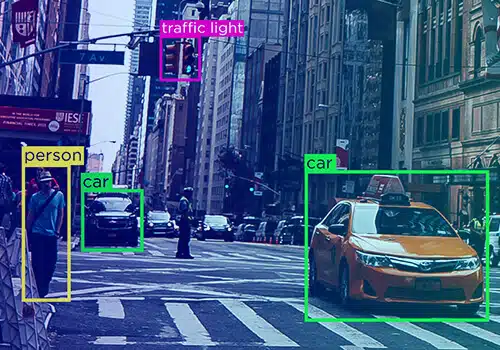 Dữ liệu không bao giờ là một thực thể duy nhất – nó có các dạng khác nhau – văn bản, video và hình ảnh. Không cần phải nói, chú thích dữ liệu có nhiều dạng khác nhau.
Dữ liệu không bao giờ là một thực thể duy nhất – nó có các dạng khác nhau – văn bản, video và hình ảnh. Không cần phải nói, chú thích dữ liệu có nhiều dạng khác nhau.
Để máy hiểu và xác định chính xác các thực thể khác nhau, điều quan trọng là phải nhấn mạnh chất lượng của Gắn thẻ thực thể được đặt tên. Một lỗi trong việc gắn thẻ và chú thích khiến ML không thể phân biệt giữa Amazon – cửa hàng thương mại điện tử, dòng sông hay con vẹt.
Bên cạnh đó, chú thích dữ liệu giúp máy móc nhận ra ý định tinh tế – một phẩm chất tự nhiên đến với con người. Chúng ta giao tiếp khác nhau và con người hiểu cả những suy nghĩ được bày tỏ rõ ràng và những thông điệp ngụ ý. Ví dụ: phản hồi hoặc đánh giá trên mạng xã hội có thể là cả tích cực và tiêu cực và ML sẽ có thể hiểu được cả hai. 'Nơi tuyệt vời. Sẽ ghé thăm một lần nữa.' Đó là một cụm từ tích cực trong khi 'Thật là một nơi tuyệt vời trước đây! Chúng tôi đã từng yêu nơi này!' là âm và chú thích của con người có thể làm cho quá trình này dễ dàng hơn nhiều.

Những thách thức trong chú thích dữ liệu và cách khắc phục chúng
Hai thách thức chính trong chú thích dữ liệu là chi phí và độ chính xác.
Nhu cầu về dữ liệu chính xác cao: Số phận của các dự án AI và ML phụ thuộc vào chất lượng của dữ liệu được chú thích. Các mô hình ML và AI phải được cung cấp một cách nhất quán với dữ liệu được phân loại tốt để có thể huấn luyện mô hình nhận ra mối tương quan giữa các biến.
Nhu cầu về số lượng lớn dữ liệu: Tất cả các mô hình ML và AI đều phát triển mạnh trên các tập dữ liệu lớn – một dự án ML đơn lẻ cần ít nhất hàng nghìn mục được gắn nhãn.
Nhu cầu về nguồn lực: Các dự án AI phụ thuộc vào tài nguyên, cả về chi phí, thời gian và lực lượng lao động. Nếu không có một trong hai điều này, chất lượng dự án chú thích dữ liệu của bạn có thể trở nên tồi tệ.
[Cũng đọc: Chú thích video cho máy học ]
Thực tiễn tốt nhất trong chú thích dữ liệu
Giá trị của chú thích dữ liệu thể hiện rõ ở tác động của nó đối với kết quả của dự án AI. Nếu tập dữ liệu mà bạn đang đào tạo các mô hình ML của mình có nhiều điểm không nhất quán, sai lệch, không cân bằng hoặc bị hỏng, thì giải pháp AI của bạn có thể thất bại. Ngoài ra, nếu các nhãn sai và chú thích không nhất quán, thì giải pháp AI cũng sẽ đưa ra các dự đoán không chính xác. Vì vậy, các thực tiễn tốt nhất trong chú thích dữ liệu là gì?
Mẹo để chú thích dữ liệu hiệu quả và hiệu quả
- Đảm bảo rằng các nhãn dữ liệu bạn tạo là cụ thể và phù hợp với nhu cầu của dự án và đủ chung chung để phục vụ cho tất cả các biến thể có thể có.
- Chú thích số lượng lớn dữ liệu cần thiết để đào tạo mô hình máy học. Bạn chú thích càng nhiều dữ liệu thì kết quả đào tạo mô hình càng tốt.
- Nguyên tắc chú thích dữ liệu đi một chặng đường dài trong việc thiết lập các tiêu chuẩn chất lượng và đảm bảo tính nhất quán trong toàn bộ dự án và trên một số trình chú thích.
- Vì chú thích dữ liệu có thể tốn kém và phụ thuộc vào nhân lực, nên việc kiểm tra các tập dữ liệu được gắn nhãn trước từ các nhà cung cấp dịch vụ là điều hợp lý.
- Để hỗ trợ đào tạo và chú thích dữ liệu chính xác, hãy mang lại hiệu quả của con người trong vòng lặp để mang lại sự đa dạng và xử lý các trường hợp quan trọng cùng với khả năng của phần mềm chú thích.
- Ưu tiên chất lượng bằng cách kiểm tra các trình chú thích về sự tuân thủ chất lượng, độ chính xác và tính nhất quán.
Tầm quan trọng của kiểm soát chất lượng trong quá trình chú thích
 Chú thích dữ liệu chất lượng là huyết mạch của các giải pháp AI hiệu suất cao. Các bộ dữ liệu được chú thích rõ ràng giúp các hệ thống AI hoạt động tốt một cách hoàn hảo, ngay cả trong một môi trường hỗn loạn. Tương tự, điều ngược lại cũng đúng như vậy. Một bộ dữ liệu có nhiều điểm không chính xác về chú thích sẽ đưa ra các giải pháp không nhất quán.
Chú thích dữ liệu chất lượng là huyết mạch của các giải pháp AI hiệu suất cao. Các bộ dữ liệu được chú thích rõ ràng giúp các hệ thống AI hoạt động tốt một cách hoàn hảo, ngay cả trong một môi trường hỗn loạn. Tương tự, điều ngược lại cũng đúng như vậy. Một bộ dữ liệu có nhiều điểm không chính xác về chú thích sẽ đưa ra các giải pháp không nhất quán.
Vì vậy, kiểm soát chất lượng trong quá trình ghi nhãn hình ảnh, video và chú thích đóng một vai trò quan trọng trong kết quả AI. Tuy nhiên, việc duy trì các tiêu chuẩn kiểm soát chất lượng cao trong suốt quá trình chú thích là một thách thức đối với các công ty quy mô lớn và nhỏ. Sự phụ thuộc vào nhiều loại công cụ chú thích và lực lượng chú thích đa dạng có thể khó đánh giá và duy trì tính nhất quán về chất lượng.
Việc duy trì chất lượng của các trình chú thích dữ liệu phân tán hoặc làm việc từ xa là rất khó khăn, đặc biệt đối với những người không quen với các tiêu chuẩn bắt buộc. Ngoài ra, việc khắc phục sự cố hoặc sửa lỗi có thể mất thời gian vì nó cần được xác định trong một lực lượng lao động phân tán.
Giải pháp sẽ là đào tạo người chú thích, liên quan đến người giám sát hoặc có nhiều người chú thích dữ liệu xem xét và đánh giá các đồng nghiệp về độ chính xác của chú thích tập dữ liệu. Cuối cùng, thường xuyên kiểm tra kiến thức của người chú giải về các tiêu chuẩn.
Vai trò của người chú thích và cách chọn người chú thích phù hợp cho dữ liệu của bạn
Người chú thích con người nắm giữ chìa khóa cho một dự án AI thành công. Người chú thích dữ liệu đảm bảo dữ liệu được chú thích chính xác, nhất quán và đáng tin cậy vì họ có thể cung cấp ngữ cảnh, hiểu ý định và đặt nền tảng cho sự thật cơ bản trong dữ liệu.
Một số dữ liệu đang được chú thích một cách giả tạo hoặc tự động với sự trợ giúp của các giải pháp tự động hóa với mức độ tin cậy khá cao. Ví dụ: bạn có thể tải xuống hàng trăm nghìn hình ảnh về các ngôi nhà từ Google và biến chúng thành bộ dữ liệu. Tuy nhiên, độ chính xác của tập dữ liệu chỉ có thể được xác định một cách đáng tin cậy sau khi mô hình bắt đầu hoạt động.
Tự động hóa tự động hóa có thể khiến mọi việc trở nên dễ dàng và nhanh chóng hơn, nhưng không thể phủ nhận, kém chính xác hơn. Mặt khác, một người chú thích con người có thể chậm hơn và tốn kém hơn, nhưng chúng chính xác hơn.
Người chú thích dữ liệu con người có thể chú thích và phân loại dữ liệu dựa trên chuyên môn về chủ đề, kiến thức bẩm sinh và đào tạo cụ thể của họ. Chú thích dữ liệu thiết lập độ chính xác, độ chính xác và tính nhất quán.
[Cũng đọc: Hướng dẫn cho người mới bắt đầu về chú thích dữ liệu: Mẹo và phương pháp hay nhất ]
Kết luận
Để tạo một dự án AI hiệu suất cao, bạn cần có dữ liệu đào tạo được chú thích chất lượng cao. Mặc dù việc có được dữ liệu được chú thích tốt một cách nhất quán có thể tốn thời gian và tài nguyên - ngay cả đối với các tập đoàn lớn - nhưng giải pháp nằm ở việc tìm kiếm dịch vụ của các nhà cung cấp dịch vụ chú thích dữ liệu lâu đời như Shaip. Tại Shaip, chúng tôi giúp bạn mở rộng khả năng AI của mình thông qua các dịch vụ chuyên gia chú thích dữ liệu của chúng tôi bằng cách đáp ứng nhu cầu của thị trường và khách hàng.


