
Trí tuệ nhân tạo, Dữ liệu lớn và Máy học tiếp tục ảnh hưởng đến các nhà hoạch định chính sách, doanh nghiệp, khoa học, nhà truyền thông và nhiều ngành công nghiệp khác nhau trên khắp thế giới. Các báo cáo cho thấy tỷ lệ chấp nhận AI trên toàn cầu hiện đang ở mức 35% trong 2022 – mức tăng khổng lồ 4% từ năm 2021. Thêm 42% công ty được báo cáo đang khám phá nhiều lợi ích của AI cho hoạt động kinh doanh của họ.
Cung cấp năng lượng cho nhiều sáng kiến AI và Machine Learning giải pháp là dữ liệu. AI chỉ có thể tốt khi dữ liệu cung cấp cho thuật toán. Dữ liệu chất lượng thấp có thể dẫn đến kết quả chất lượng thấp và dự đoán không chính xác.
Mặc dù đã có rất nhiều sự chú ý về phát triển giải pháp ML và AI, nhưng nhận thức về những gì đủ điều kiện là một bộ dữ liệu chất lượng vẫn còn thiếu. Trong bài viết này, chúng tôi điều hướng dòng thời gian của dữ liệu đào tạo AI chất lượng và xác định tương lai của AI thông qua sự hiểu biết về thu thập và đào tạo dữ liệu.
Định nghĩa dữ liệu đào tạo AI
Khi xây dựng một giải pháp ML, số lượng và chất lượng của tập dữ liệu huấn luyện rất quan trọng. Hệ thống ML không chỉ yêu cầu khối lượng lớn dữ liệu đào tạo động, không thiên vị và có giá trị mà còn cần rất nhiều dữ liệu đó.
Nhưng dữ liệu đào tạo AI là gì?
Dữ liệu đào tạo AI là tập hợp dữ liệu được gắn nhãn dùng để đào tạo thuật toán ML nhằm đưa ra dự đoán chính xác. Hệ thống ML cố gắng nhận dạng và xác định các mẫu, hiểu mối quan hệ giữa các tham số, đưa ra các quyết định cần thiết và đánh giá dựa trên dữ liệu đào tạo.
Lấy ví dụ về xe tự lái chẳng hạn. Bộ dữ liệu đào tạo cho mô hình ML tự lái phải bao gồm các hình ảnh và video được dán nhãn về ô tô, người đi bộ, biển báo đường phố và các phương tiện khác.
Nói tóm lại, để nâng cao chất lượng của thuật toán ML, bạn cần một lượng lớn dữ liệu đào tạo có cấu trúc tốt, được chú thích và được gắn nhãn.
Tầm quan trọng của dữ liệu đào tạo chất lượng và sự phát triển của nó
Dữ liệu đào tạo chất lượng cao là đầu vào chính trong quá trình phát triển ứng dụng AI và ML. Dữ liệu được thu thập từ nhiều nguồn khác nhau và được trình bày ở dạng không có tổ chức, không phù hợp với mục đích học máy. Dữ liệu đào tạo chất lượng – được gắn nhãn, chú thích và gắn thẻ – luôn ở định dạng có tổ chức – lý tưởng cho đào tạo ML.
Dữ liệu đào tạo chất lượng giúp hệ thống ML dễ dàng nhận ra các đối tượng và phân loại chúng theo các tính năng được xác định trước. Bộ dữ liệu có thể mang lại kết quả mô hình xấu nếu phân loại không chính xác.
Những ngày đầu của dữ liệu đào tạo AI
Mặc dù AI thống trị thế giới nghiên cứu và kinh doanh hiện tại, nhưng những ngày đầu trước khi ML thống trị Trí tuệ nhân tạo là khá khác nhau.
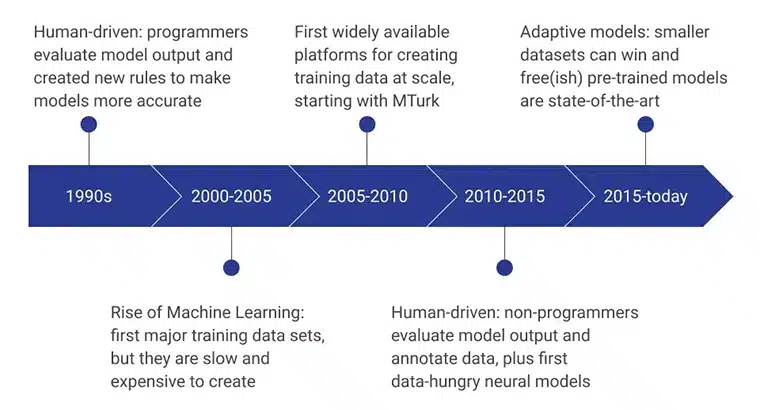
Các giai đoạn đầu của dữ liệu đào tạo AI được cung cấp bởi các lập trình viên con người, những người đã đánh giá đầu ra của mô hình bằng cách liên tục đưa ra các quy tắc mới giúp mô hình hiệu quả hơn. Trong giai đoạn 2000 – 2005, tập dữ liệu lớn đầu tiên được tạo ra và đó là một quy trình cực kỳ chậm, phụ thuộc vào tài nguyên và tốn kém. Nó dẫn đến các bộ dữ liệu đào tạo được phát triển trên quy mô lớn và MTurk của Amazon đóng một vai trò quan trọng trong việc thay đổi nhận thức của mọi người đối với việc thu thập dữ liệu. Đồng thời, việc ghi nhãn và chú thích của con người cũng được thực hiện.
Vài năm tới tập trung vào việc tạo và đánh giá các mô hình dữ liệu của những người không phải là lập trình viên. Hiện tại, trọng tâm là các mô hình đào tạo trước được phát triển bằng các phương pháp thu thập dữ liệu đào tạo nâng cao.
Số lượng hơn chất lượng
Khi đánh giá tính toàn vẹn của bộ dữ liệu đào tạo AI ngày trước, các nhà khoa học dữ liệu tập trung vào Số lượng dữ liệu đào tạo AI quá chất lượng.
Ví dụ, có một quan niệm sai lầm phổ biến rằng cơ sở dữ liệu lớn mang lại kết quả chính xác. Khối lượng dữ liệu tuyệt đối được cho là một chỉ báo tốt về giá trị của dữ liệu. Số lượng chỉ là một trong những yếu tố chính quyết định giá trị của tập dữ liệu – vai trò của chất lượng dữ liệu đã được công nhận.
Nhận thức rằng chất lượng dữ liệu phụ thuộc vào tính đầy đủ của dữ liệu, độ tin cậy, hiệu lực, tính sẵn có và tính kịp thời tăng lên. Quan trọng nhất, sự phù hợp của dữ liệu cho dự án quyết định chất lượng của dữ liệu được thu thập.
Hạn chế của các hệ thống AI ban đầu do dữ liệu đào tạo kém
Dữ liệu đào tạo kém, cùng với việc thiếu các hệ thống máy tính tiên tiến, là một trong những lý do dẫn đến một số lời hứa không thành hiện thực về các hệ thống AI ban đầu.
Do thiếu dữ liệu đào tạo chất lượng, các giải pháp ML không thể xác định chính xác các mẫu hình ảnh làm cản trở sự phát triển của nghiên cứu thần kinh. Mặc dù nhiều nhà nghiên cứu đã xác định được triển vọng nhận dạng ngôn ngữ nói, nhưng việc nghiên cứu hoặc phát triển các công cụ nhận dạng giọng nói không thể thành hiện thực do thiếu bộ dữ liệu giọng nói. Một trở ngại lớn khác đối với việc phát triển các công cụ AI cao cấp là máy tính thiếu khả năng tính toán và lưu trữ.
Chuyển sang dữ liệu đào tạo chất lượng
Đã có một sự thay đổi rõ rệt trong nhận thức rằng chất lượng của tập dữ liệu là quan trọng. Để hệ thống ML bắt chước chính xác trí thông minh của con người và khả năng ra quyết định, nó phải phát triển dựa trên dữ liệu đào tạo chất lượng cao, khối lượng lớn.
Hãy nghĩ về dữ liệu ML của bạn như một cuộc khảo sát – dữ liệu càng lớn mẫu dữ liệu càng lớn thì dự đoán càng tốt. Nếu dữ liệu mẫu không bao gồm tất cả các biến, nó có thể không nhận ra các mẫu hoặc đưa ra kết luận không chính xác.
Những tiến bộ trong công nghệ AI và nhu cầu về dữ liệu đào tạo tốt hơn
 Những tiến bộ trong công nghệ AI đang làm tăng nhu cầu về dữ liệu đào tạo chất lượng.
Những tiến bộ trong công nghệ AI đang làm tăng nhu cầu về dữ liệu đào tạo chất lượng.Việc hiểu rằng dữ liệu đào tạo tốt hơn làm tăng cơ hội tạo ra các mô hình ML đáng tin cậy đã tạo ra các phương pháp thu thập, chú thích và ghi nhãn dữ liệu tốt hơn. Chất lượng và mức độ liên quan của dữ liệu ảnh hưởng trực tiếp đến chất lượng của mô hình AI.
 Những tiến bộ trong công nghệ AI đang làm tăng nhu cầu về dữ liệu đào tạo chất lượng.
Những tiến bộ trong công nghệ AI đang làm tăng nhu cầu về dữ liệu đào tạo chất lượng.Tăng cường tập trung vào chất lượng và độ chính xác của dữ liệu
Để mô hình ML bắt đầu cung cấp kết quả chính xác, nó được cung cấp trên các bộ dữ liệu chất lượng trải qua các bước tinh chỉnh dữ liệu lặp đi lặp lại.
Ví dụ: một người có thể nhận ra một giống chó cụ thể trong vòng vài ngày sau khi được giới thiệu về giống chó này – thông qua hình ảnh, video hoặc gặp trực tiếp. Con người rút ra từ kinh nghiệm của họ và thông tin liên quan để ghi nhớ và lấy kiến thức này khi cần thiết. Tuy nhiên, nó không hoạt động dễ dàng đối với Máy móc. Máy phải được cung cấp các hình ảnh được chú thích và dán nhãn rõ ràng – hàng trăm hoặc hàng nghìn – của giống chó cụ thể đó và các giống chó khác để nó tạo kết nối.
Một mô hình AI dự đoán kết quả bằng cách tương quan giữa thông tin được đào tạo với thông tin được trình bày trong thế giới thực. Thuật toán trở nên vô dụng nếu dữ liệu đào tạo không bao gồm thông tin liên quan.
Tầm quan trọng của dữ liệu đào tạo đa dạng và đại diện
Sự đa dạng dữ liệu tăng lên cũng làm tăng năng lực, giảm sự thiên vị và tăng cường sự thể hiện công bằng cho tất cả các tình huống. Nếu mô hình AI được đào tạo bằng tập dữ liệu đồng nhất, bạn có thể chắc chắn rằng ứng dụng mới sẽ chỉ hoạt động cho một mục đích cụ thể và phục vụ một nhóm dân số cụ thể.Một bộ dữ liệu có thể thiên về một dân số, chủng tộc, giới tính, sự lựa chọn và quan điểm trí tuệ cụ thể, điều này có thể dẫn đến một mô hình không chính xác.
Điều quan trọng là đảm bảo toàn bộ quy trình thu thập dữ liệu, bao gồm chọn nhóm chủ đề, sắp xếp, chú thích và ghi nhãn, đa dạng, cân bằng và đại diện đầy đủ cho dân số.
 Sự đa dạng dữ liệu tăng lên cũng làm tăng năng lực, giảm sự thiên vị và tăng cường sự thể hiện công bằng cho tất cả các tình huống. Nếu mô hình AI được đào tạo bằng tập dữ liệu đồng nhất, bạn có thể chắc chắn rằng ứng dụng mới sẽ chỉ hoạt động cho một mục đích cụ thể và phục vụ một nhóm dân số cụ thể.
Sự đa dạng dữ liệu tăng lên cũng làm tăng năng lực, giảm sự thiên vị và tăng cường sự thể hiện công bằng cho tất cả các tình huống. Nếu mô hình AI được đào tạo bằng tập dữ liệu đồng nhất, bạn có thể chắc chắn rằng ứng dụng mới sẽ chỉ hoạt động cho một mục đích cụ thể và phục vụ một nhóm dân số cụ thể.Tương lai của dữ liệu đào tạo AI
Sự thành công trong tương lai của các mô hình AI phụ thuộc vào chất lượng và số lượng dữ liệu đào tạo được sử dụng để đào tạo các thuật toán ML. Điều quan trọng là phải nhận ra rằng mối quan hệ này giữa chất lượng và số lượng dữ liệu là dành riêng cho từng nhiệm vụ và không có câu trả lời chắc chắn.
Cuối cùng, tính đầy đủ của tập dữ liệu huấn luyện được xác định bởi khả năng hoạt động tốt một cách đáng tin cậy cho mục đích mà nó được xây dựng.
Những tiến bộ trong kỹ thuật thu thập và chú thích dữ liệu
Vì ML rất nhạy cảm với dữ liệu được cung cấp, nên điều quan trọng là hợp lý hóa các chính sách thu thập và chú thích dữ liệu. Lỗi trong việc thu thập dữ liệu, quản lý, trình bày sai, đo lường không đầy đủ, nội dung không chính xác, trùng lặp dữ liệu và đo lường sai góp phần làm cho chất lượng dữ liệu không đầy đủ.
Thu thập dữ liệu tự động thông qua khai thác dữ liệu, quét web và trích xuất dữ liệu đang mở đường cho việc tạo dữ liệu nhanh hơn. Ngoài ra, các bộ dữ liệu được đóng gói sẵn hoạt động như một kỹ thuật thu thập dữ liệu khắc phục nhanh.
Crowdsourcing là một phương pháp đột phá khác để thu thập dữ liệu. Mặc dù không thể đảm bảo tính xác thực của dữ liệu, nhưng nó là một công cụ tuyệt vời để thu thập hình ảnh công khai. Cuối cùng, chuyên ngành thu thập dữ liệu các chuyên gia cũng cung cấp dữ liệu có nguồn gốc cho các mục đích cụ thể.
Tăng cường nhấn mạnh vào các cân nhắc về đạo đức trong dữ liệu đào tạo
Với những tiến bộ nhanh chóng trong AI, một số vấn đề đạo đức đã nảy sinh, đặc biệt là trong việc thu thập dữ liệu đào tạo. Một số cân nhắc về đạo đức trong việc thu thập dữ liệu đào tạo bao gồm sự đồng ý có hiểu biết, tính minh bạch, sự thiên vị và quyền riêng tư của dữ liệu.Vì dữ liệu hiện bao gồm mọi thứ từ hình ảnh khuôn mặt, dấu vân tay, bản ghi âm giọng nói và dữ liệu sinh trắc học quan trọng khác, nên việc đảm bảo tuân thủ các thông lệ pháp lý và đạo đức để tránh các vụ kiện tốn kém và tổn hại đến danh tiếng trở nên cực kỳ quan trọng.
Tiềm năng cho chất lượng tốt hơn và dữ liệu đào tạo đa dạng hơn trong tương lai
Có một tiềm năng rất lớn cho dữ liệu đào tạo chất lượng cao và đa dạng trong tương lai. Nhờ nhận thức về chất lượng dữ liệu và sự sẵn có của các nhà cung cấp dữ liệu đáp ứng nhu cầu về chất lượng của các giải pháp AI.
Các nhà cung cấp dữ liệu hiện tại rất thành thạo trong việc sử dụng các công nghệ đột phá để tạo nguồn số lượng lớn các bộ dữ liệu đa dạng một cách có đạo đức và hợp pháp. Họ cũng có các nhóm nội bộ để gắn nhãn, chú thích và trình bày dữ liệu được tùy chỉnh cho các dự án ML khác nhau.
 Với những tiến bộ nhanh chóng trong AI, một số vấn đề đạo đức đã nảy sinh, đặc biệt là trong việc thu thập dữ liệu đào tạo. Một số cân nhắc về đạo đức trong việc thu thập dữ liệu đào tạo bao gồm sự đồng ý có hiểu biết, tính minh bạch, sự thiên vị và quyền riêng tư của dữ liệu.
Với những tiến bộ nhanh chóng trong AI, một số vấn đề đạo đức đã nảy sinh, đặc biệt là trong việc thu thập dữ liệu đào tạo. Một số cân nhắc về đạo đức trong việc thu thập dữ liệu đào tạo bao gồm sự đồng ý có hiểu biết, tính minh bạch, sự thiên vị và quyền riêng tư của dữ liệu.Kết luận
Điều quan trọng là phải hợp tác với các nhà cung cấp đáng tin cậy với sự hiểu biết sâu sắc về dữ liệu và chất lượng để phát triển các mô hình AI cao cấp. Shaip là công ty chú thích hàng đầu chuyên cung cấp các giải pháp dữ liệu tùy chỉnh đáp ứng nhu cầu và mục tiêu dự án AI của bạn. Hợp tác với chúng tôi và khám phá năng lực, cam kết và sự hợp tác mà chúng tôi mang lại.


