
Dữ liệu là siêu cường đang làm thay đổi cảnh quan kỹ thuật số trong thế giới ngày nay. Từ email đến các bài đăng trên mạng xã hội, có dữ liệu ở khắp mọi nơi. Đúng là doanh nghiệp chưa bao giờ được tiếp cận nhiều dữ liệu như vậy, nhưng liệu có đủ quyền truy cập vào dữ liệu hay không? Nguồn thông tin phong phú trở nên vô dụng hoặc lỗi thời khi nó không được xử lý.
Văn bản phi cấu trúc có thể là một nguồn thông tin phong phú, nhưng nó sẽ không hữu ích cho các doanh nghiệp trừ khi dữ liệu được sắp xếp, phân loại và phân tích. Dữ liệu phi cấu trúc, chẳng hạn như văn bản, âm thanh, video và phương tiện truyền thông xã hội, 80 -90% của tất cả dữ liệu. Hơn nữa, chỉ có 18% tổ chức được báo cáo là đang tận dụng dữ liệu phi cấu trúc của tổ chức họ.
Việc sàng lọc thủ công từng terabyte dữ liệu được lưu trữ trong các máy chủ là một nhiệm vụ tốn thời gian và thực sự là bất khả thi. Tuy nhiên, với những tiến bộ trong học máy, xử lý ngôn ngữ tự nhiên và tự động hóa, có thể cấu trúc và phân tích dữ liệu văn bản một cách nhanh chóng và hiệu quả. Bước đầu tiên trong phân tích dữ liệu là phân loại văn bản.
Phân loại Văn bản là gì?
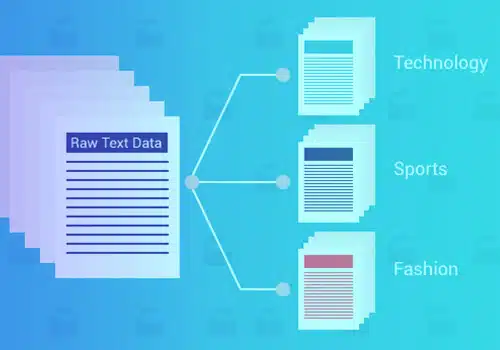
Phân loại hoặc phân loại văn bản là quá trình nhóm văn bản thành các danh mục hoặc lớp được xác định trước. Sử dụng phương pháp học máy này, bất kỳ văn bản – tài liệu, tệp web, nghiên cứu, tài liệu pháp lý, báo cáo y tế, v.v. - có thể được phân loại, tổ chức và cấu trúc.
Phân loại văn bản là bước cơ bản trong xử lý ngôn ngữ tự nhiên có một số ứng dụng trong phát hiện thư rác. Phân tích tình cảm, phát hiện ý định, ghi nhãn dữ liệu, v.v..
Các trường hợp sử dụng có thể có của phân loại văn bản
 Có một số lợi ích khi sử dụng phân loại văn bản bằng máy học, chẳng hạn như khả năng mở rộng, tốc độ phân tích, tính nhất quán và khả năng đưa ra quyết định nhanh chóng dựa trên các cuộc trò chuyện thời gian thực.
Có một số lợi ích khi sử dụng phân loại văn bản bằng máy học, chẳng hạn như khả năng mở rộng, tốc độ phân tích, tính nhất quán và khả năng đưa ra quyết định nhanh chóng dựa trên các cuộc trò chuyện thời gian thực.
Khi mô hình ML được đào tạo về AI tự động phân loại các mục theo các danh mục đặt trước, bạn có thể nhanh chóng chuyển đổi các trình duyệt thông thường thành khách hàng.
Quy trình phân loại văn bản
Quá trình phân loại văn bản bắt đầu với việc xử lý trước, lựa chọn tính năng, trích xuất và phân loại dữ liệu.

Sơ chế
Mã hóa: Văn bản được chia thành các dạng văn bản nhỏ hơn và đơn giản hơn để dễ dàng phân loại.
Bình thường hóa: Tất cả văn bản trong một tài liệu cần ở cùng một mức độ hiểu. Một số hình thức chuẩn hóa bao gồm,
- Duy trì các tiêu chuẩn ngữ pháp hoặc cấu trúc trên toàn văn bản, chẳng hạn như loại bỏ khoảng trắng hoặc dấu chấm câu. Hoặc duy trì các chữ thường trong suốt văn bản.
- Loại bỏ các tiền tố và hậu tố khỏi các từ và đưa chúng trở lại từ gốc của chúng.
- Loại bỏ các từ dừng như 'và' 'là' 'sự' và các từ khác không làm tăng giá trị cho văn bản.
Lựa chọn tính năng
Lựa chọn đối tượng là một bước cơ bản trong phân loại văn bản. Quá trình này nhằm mục đích đại diện cho các văn bản có tính năng phù hợp nhất. Lựa chọn tính năng giúp loại bỏ dữ liệu không liên quan và nâng cao độ chính xác.
Lựa chọn tính năng làm giảm biến đầu vào vào mô hình bằng cách chỉ sử dụng dữ liệu phù hợp nhất và loại bỏ nhiễu. Dựa trên loại giải pháp bạn tìm kiếm, các mô hình AI của bạn có thể được thiết kế để chỉ chọn các tính năng có liên quan từ văn bản.
Khai thác tính năng
Trích xuất tính năng là một bước tùy chọn mà một số doanh nghiệp thực hiện để trích xuất các tính năng chính bổ sung trong dữ liệu. Trích xuất đối tượng sử dụng một số kỹ thuật, chẳng hạn như ánh xạ, lọc và phân cụm. Lợi ích chính của việc sử dụng tính năng trích xuất là - nó giúp loại bỏ dữ liệu dư thừa và cải thiện tốc độ phát triển mô hình ML.
Gắn thẻ dữ liệu vào danh mục được xác định trước
Gắn thẻ văn bản vào các danh mục được xác định trước là bước cuối cùng trong phân loại văn bản. Nó có thể được thực hiện theo ba cách khác nhau,
- Gắn thẻ thủ công
- Đối sánh dựa trên quy tắc
- Thuật toán học tập - Các thuật toán học tập có thể được phân loại thành hai loại như gắn thẻ được giám sát và gắn thẻ không được giám sát.
- Học tập có giám sát: Mô hình ML có thể tự động căn chỉnh các thẻ với dữ liệu được phân loại hiện có trong gắn thẻ được giám sát. Khi dữ liệu được phân loại đã có sẵn, các thuật toán ML có thể ánh xạ chức năng giữa các thẻ và văn bản.
- Học không giám sát: Điều này xảy ra khi thiếu dữ liệu được gắn thẻ hiện có trước đó. Mô hình ML sử dụng thuật toán phân cụm và dựa trên quy tắc để nhóm các văn bản tương tự, chẳng hạn như dựa trên lịch sử mua sản phẩm, đánh giá, chi tiết cá nhân và vé. Các nhóm rộng này có thể được phân tích thêm để rút ra những hiểu biết sâu sắc có giá trị về khách hàng cụ thể có thể được sử dụng để thiết kế các phương pháp tiếp cận khách hàng phù hợp.
Có nhiều trường hợp sử dụng để phân loại văn bản giữa các ngành. Mặc dù việc thu thập, nhóm, phân loại và trích xuất những hiểu biết có giá trị từ dữ liệu văn bản luôn được sử dụng trong một số lĩnh vực, nhưng phân loại văn bản đang tìm thấy tiềm năng của nó trong tiếp thị, phát triển sản phẩm, dịch vụ khách hàng, quản lý và điều hành. Nó đang giúp các doanh nghiệp có được trí tuệ cạnh tranh, hiểu biết về thị trường và khách hàng, đồng thời đưa ra các quyết định kinh doanh dựa trên dữ liệu.
Phát triển một công cụ phân loại văn bản hiệu quả và sâu sắc là không dễ dàng. Tuy nhiên, với Shaip là đối tác dữ liệu của bạn, bạn có thể phát triển một công cụ phân loại văn bản dựa trên AI hiệu quả, có thể mở rộng và tiết kiệm chi phí. Chúng tôi có hàng tấn bộ dữ liệu được chú thích chính xác và sẵn sàng sử dụng có thể được tùy chỉnh cho các yêu cầu duy nhất của mô hình của bạn. Chúng tôi biến văn bản của bạn thành một lợi thế cạnh tranh; liên lạc ngay hôm nay.


