Giấy phép Dữ liệu y tế / chăm sóc sức khỏe chất lượng cao cho các mô hình AI & ML
Bộ dữ liệu y tế / chăm sóc sức khỏe có sẵn để bắt đầu dự án AI chăm sóc sức khỏe của bạn

Cắm vào dữ liệu y tế bạn đã bỏ lỡ ngày hôm nay
Bộ dữ liệu y tế và chăm sóc sức khỏe cho Máy học
Dữ liệu âm thanh đọc chính tả của bác sĩ
Bộ dữ liệu chưa được xác định của chúng tôi dành cho chăm sóc sức khỏe bao gồm 31 tệp âm thanh chuyên khoa khác nhau do các bác sĩ mô tả tình trạng lâm sàng của bệnh nhân và kế hoạch chăm sóc dựa trên các cuộc gặp gỡ giữa bác sĩ và bệnh nhân trong bệnh viện / cơ sở lâm sàng.
Tệp âm thanh đọc chính tả của bác sĩ ngoại khoa:
- 257,977 giờ Tập dữ liệu bài phát biểu của bác sĩ trong thế giới thực từ 31 chuyên khoa 'để đào tạo các mô hình bài phát biểu trong chăm sóc sức khỏe
- Âm thanh đọc chính tả được ghi lại từ các thiết bị khác nhau như Telephone Dictation (54.3%), Máy ghi âm kỹ thuật số (24.9%), Mic nói (5.4%), Điện thoại thông minh (2.7%) và Không xác định (12.7%)
- PII âm thanh và bản ghi đã được biên dịch lại tuân theo Nguyên tắc che giấu an toàn tuân theo HIPAA

Hồ sơ y tế được chép lại
Transcribed medical records refers to transcription of physician and patient conversation, transcription of medical reports and medical assessment. It helps in mapping the medical history of the patient for future visits and also acts as a refence point for the doctors. It helps the doctor to evaluate the present condition of the patient and suggest a suitable treatment.
Hồ sơ y tế được sao chép không có giá trị:
- Phiên âm 257,977 giờ diễn thuyết của bác sĩ trong thế giới thực từ 31 chuyên khoa để đào tạo các mô hình Bài phát biểu trong chăm sóc sức khỏe
- Hồ sơ Y tế được sao chép từ nhiều loại công việc khác nhau như Báo cáo hoạt động, Tóm tắt xuất viện, Ghi chú tư vấn, Ghi chú nhập học, Ghi chú ED, Ghi chú Phòng khám, Báo cáo X quang, v.v.
- PII âm thanh và bản ghi đã được biên dịch lại tuân theo Nguyên tắc che giấu an toàn tuân theo HIPAA

Hồ sơ sức khỏe điện tử (EHR)
Hồ sơ sức khỏe điện tử hoặc EHR là hồ sơ y tế chứa lịch sử y tế của bệnh nhân, chẩn đoán, đơn thuốc, kế hoạch điều trị, ngày tiêm chủng hoặc chủng ngừa, dị ứng, hình ảnh X quang (CT Scan, MRI, X-Rays) và các xét nghiệm trong phòng thí nghiệm và hơn thế nữa.
Hồ sơ sức khỏe điện tử có sẵn (EHR):
- 5.1M + Bản ghi và tệp âm thanh bác sĩ trong 31 chuyên khoa
- Hồ sơ y tế tiêu chuẩn vàng trong thế giới thực để đào tạo NLP lâm sàng và các mô hình AI tài liệu khác
- Thông tin siêu dữ liệu như MRN (Ẩn danh), Ngày nhập học, Ngày xuất viện, Thời gian lưu trú, Giới tính, Hạng bệnh nhân, Người thanh toán, Hạng tài chính, Tiểu bang, Xử lý xuất viện, Tuổi, DRG, Mô tả DRG, Khoản hoàn trả $, AMLOS, GMLOS, Rủi ro tỷ lệ tử vong, Mức độ nghiêm trọng của bệnh tật, Cá mú, Mã Zip bệnh viện, v.v.
- Hồ sơ Y tế từ các tiểu bang và khu vực khác nhau của Hoa Kỳ - Đông Bắc (46%), Nam (9%), Trung Tây (3%), Tây (28%), Các vùng khác (14%)
- Hồ sơ Y tế thuộc tất cả các Hạng bệnh nhân được bảo hiểm- Nội trú, Ngoại trú (Lâm sàng, Phục hồi chức năng, Định kỳ, Chăm sóc ban ngày phẫu thuật), Cấp cứu.
- Hồ sơ bệnh án thuộc tất cả các Nhóm tuổi bệnh nhân <10 tuổi (7.9%), 11-20 tuổi (5.7%), 21-30 tuổi (10.9%), 31-40 tuổi (11.7%), 41-50 tuổi (10.4%) ), 51-60 tuổi (13.8%), 61-70 tuổi (16.1%), 71-80 tuổi (13.3%), 81-90 tuổi (7.8%), 90+ tuổi (2.4%)
- Tỷ lệ giới tính của bệnh nhân là 46% (Nam) và 54% (Nữ)
- Tài liệu được biên tập lại PII tuân theo Nguyên tắc che giấu an toàn tuân theo HIPAA

- Hồ sơ bệnh án thuộc tất cả các Nhóm tuổi bệnh nhân <10 tuổi (7.9%), 11-20 tuổi (5.7%), 21-30 tuổi (10.9%), 31-40 tuổi (11.7%), 41-50 tuổi (10.4%) ), 51-60 tuổi (13.8%), 61-70 tuổi (16.1%), 71-80 tuổi (13.3%), 81-90 tuổi (7.8%), 90+ tuổi (2.4%)
- Tỷ lệ giới tính của bệnh nhân là 46% (Nam) và 54% (Nữ)
- Tài liệu được biên tập lại PII tuân theo Nguyên tắc che giấu an toàn tuân theo HIPAA
Bộ dữ liệu hình ảnh CT Scan
Các bác sĩ sử dụng hình ảnh chụp CT để chẩn đoán và phát hiện các tình trạng bất thường hoặc bình thường trong cơ thể bệnh nhân (nghĩa là xác định bệnh hoặc chấn thương trong các bộ phận cơ thể khác nhau). Trong chẩn đoán xử lý hình ảnh trên máy vi tính, hình ảnh CT-scan trải qua các giai đoạn tinh vi, tức là, thu nhận, nâng cao hình ảnh, trích xuất các tính năng quan trọng, nhận dạng Vùng quan tâm (ROI), giải thích kết quả, v.v.
Shaip provides high-quality CT scan image datasets essential for research and medical diagnosis. Our datasets include thousands of high-resolution images collected from real patients and processed with state-of-the-art techniques. These datasets are designed to help medical professionals and researchers improve their knowledge and understanding of various medical conditions, including cancer, neurological disorders, and cardiovascular diseases. With Shaip, you can access reliable and accurate medical data to enhance your research and improve patient outcomes.
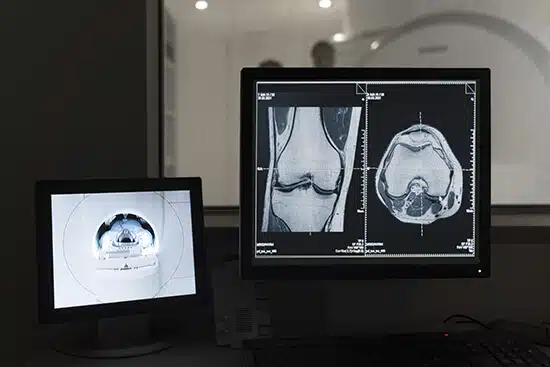
Bộ dữ liệu hình ảnh MRI
Computer vision models are designed to derive meaningful information from digital images and videos, according to IBM. It allows extensive use of healthcare image data to provide better diagnosis, treatment, and prediction of diseases. It can use context from the image sequence, texture, shape, and contour information, as well as past knowledge, to produce 3D and 4D information that aids in improved human understanding. Like CT scans, MRIs are also used to diagnose and detect abnormal or normal conditions in a patient’s body (i.e., to identify disease or injury within various body parts).
Shaip provides high-quality MRI image datasets essential for research and medical diagnosis. Our datasets include thousands of high-resolution images collected from real patients and processed with state-of-the-art techniques.

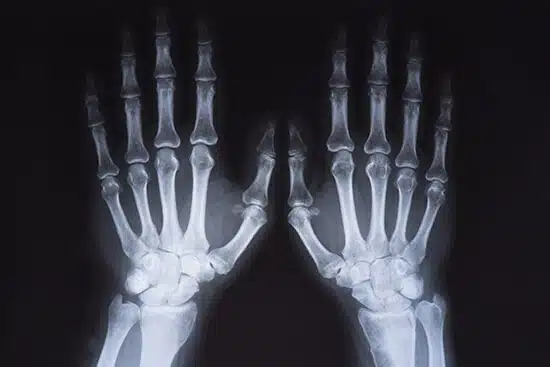
Bộ dữ liệu hình ảnh X-Ray
Thử nghiệm tia X được sử dụng để xác minh cấu trúc bên trong và tính toàn vẹn của đối tượng. Hình ảnh X-quang của một đối tượng thử nghiệm có thể được tạo ra ở các vị trí khác nhau và các mức năng lượng khác nhau để chẩn đoán và phát hiện các tình trạng bất thường trong cơ thể bệnh nhân.
Shaip cung cấp bộ dữ liệu hình ảnh X-Ray chất lượng cao cần thiết cho nghiên cứu và chẩn đoán y tế. Bộ dữ liệu của chúng tôi bao gồm hàng nghìn hình ảnh có độ phân giải cao được thu thập từ các bệnh nhân thực và được xử lý bằng các kỹ thuật tiên tiến nhất. Với Shaip, bạn có thể truy cập dữ liệu y tế chính xác và đáng tin cậy để tăng cường nghiên cứu và cải thiện kết quả của bệnh nhân.

Không thể tìm thấy những gì bạn đang tìm kiếm?
Bộ dữ liệu y tế mới có sẵn đang được thu thập trên tất cả các loại dữ liệu
Liên hệ với chúng tôi ngay bây giờ để loại bỏ những lo lắng về thu thập dữ liệu đào tạo chăm sóc sức khỏe của bạn
Những câu hỏi thường gặp (FAQ)
A healthcare dataset is a collection of health-related data, often structured and gathered for analysis, research, and decision-making in medical and healthcare domains.
Examples include electronic health records (EHRs), medical imaging databases, genomic sequences, patient demographics, and datasets from wearable health devices.
Healthcare datasets support medical research by providing insights into disease patterns, treatment outcomes, patient behavior, drug efficacy, and more, thereby aiding in medical advancements and policy formation.
Common formats include CSV, Excel, DICOM (for medical imaging), and HL7 (for health records).
Privacy concerns arise from the potential misuse of sensitive patient data, leading to identity theft, discrimination, or unwanted exposure to personal health information.
Patient information is protected using de-identification (removing personally identifiable information), encryption, strict access controls, and adherence to regulations like HIPAA (in the U.S.).
To ensure quality, regularly validate and clean the dataset, use standardized data collection methods, cross-reference with reliable sources, and involve domain experts for verification.