



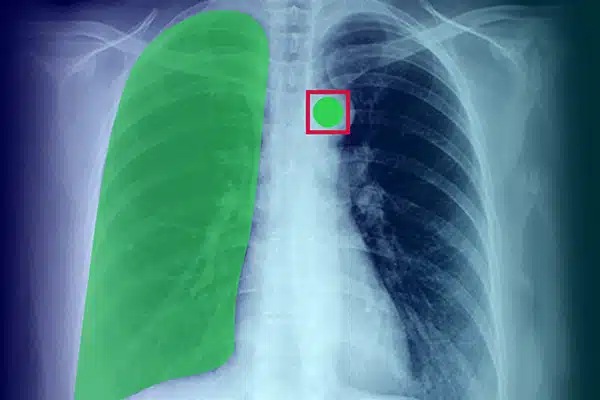
Chú thích Hình ảnh
Nâng cao AI y tế bằng cách chú thích dữ liệu trực quan từ tia X, ảnh chụp CT và MRI. Đảm bảo các mô hình AI hoạt động xuất sắc trong chẩn đoán và điều trị, được hướng dẫn bởi việc ghi nhãn dữ liệu của chuyên gia. Nhận được kết quả tốt hơn cho bệnh nhân nhờ những hiểu biết sâu sắc về hình ảnh.
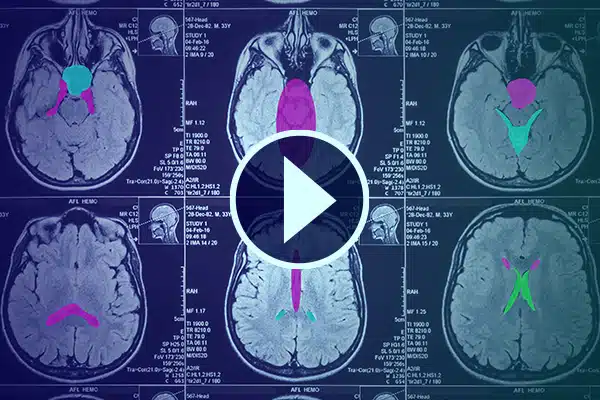
Chú thích Video
Nâng cao AI trong chăm sóc sức khỏe với chú thích video chi tiết. Nâng cao khả năng học tập của AI bằng cách phân loại và phân đoạn trong cảnh quay y tế. Cải thiện AI phẫu thuật và theo dõi bệnh nhân để cải thiện việc cung cấp dịch vụ chăm sóc sức khỏe và chẩn đoán.
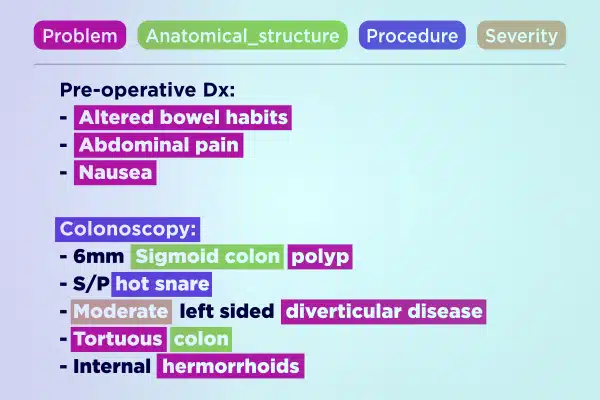
Chú thích Văn bản
Hợp lý hóa quá trình phát triển AI y tế với dữ liệu văn bản được chú thích chuyên nghiệp. Nhanh chóng phân tích cú pháp và làm phong phú khối lượng văn bản khổng lồ, từ ghi chú viết tay đến báo cáo bảo hiểm. Đảm bảo những hiểu biết chính xác và hữu ích cho những tiến bộ trong lĩnh vực chăm sóc sức khỏe.

Chú thích âm thanh
Tận dụng chuyên môn NLP để chú thích và gắn nhãn dữ liệu âm thanh y tế một cách chính xác. Tạo ra các hệ thống hỗ trợ bằng giọng nói để thực hiện các hoạt động lâm sàng liền mạch và tích hợp AI vào các sản phẩm chăm sóc sức khỏe được kích hoạt bằng giọng nói khác nhau. Nâng cao độ chính xác của chẩn đoán bằng cách quản lý dữ liệu âm thanh chuyên nghiệp.

Mã hóa y tế
Hợp lý hóa tài liệu y tế bằng cách chuyển đổi nó thành mã phổ quát bằng mã hóa y tế AI. Đảm bảo độ chính xác, nâng cao hiệu quả thanh toán và hỗ trợ cung cấp dịch vụ chăm sóc sức khỏe liền mạch với sự hỗ trợ AI tiên tiến trong mã hóa hồ sơ y tế.

Giai đoạn 1: Chuyên môn về lĩnh vực kỹ thuật (Hiểu phạm vi và nguyên tắc chú thích)

Giai đoạn 2: Đào tạo các nguồn lực phù hợp cho dự án

Giai đoạn 3: Chu kỳ phản hồi và QA của các tài liệu được chú thích
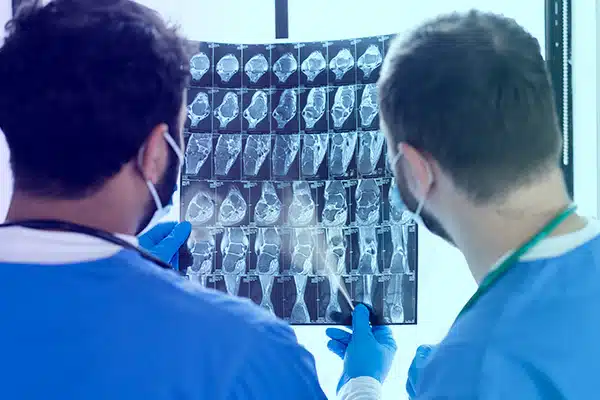
Radiology
Dịch vụ chú thích hình ảnh X quang của chúng tôi giúp nâng cao khả năng chẩn đoán bằng AI và bao gồm thêm một lớp kiến thức chuyên môn. Mỗi lần chụp X-quang, MRI và CT đều được chuyên gia về chủ đề đó dán nhãn và xem xét tỉ mỉ. Bước bổ sung trong đào tạo và đánh giá này giúp tăng cường khả năng của AI trong việc phát hiện các bất thường và bệnh tật. Nó nâng cao độ chính xác trước khi giao hàng cho khách hàng của chúng tôi.

Tim mạch
Chú thích hình ảnh tập trung vào tim mạch của chúng tôi giúp nâng cao khả năng chẩn đoán bằng AI. Chúng tôi mời các chuyên gia tim mạch gắn nhãn các hình ảnh phức tạp liên quan đến tim và đào tạo các mô hình AI của chúng tôi. Trước khi chúng tôi gửi dữ liệu cho khách hàng, các chuyên gia này sẽ xem xét từng hình ảnh để đảm bảo độ chính xác cao nhất. Quá trình này cho phép AI phát hiện bệnh tim chính xác hơn.
Nha khoa
Dịch vụ chú thích hình ảnh của chúng tôi trong nha khoa gắn nhãn hình ảnh nha khoa để nâng cao các công cụ chẩn đoán AI. Bằng cách xác định chính xác sâu răng, các vấn đề về căn chỉnh và các tình trạng nha khoa khác, các doanh nghiệp vừa và nhỏ của chúng tôi hỗ trợ AI để cải thiện kết quả của bệnh nhân và hỗ trợ nha sĩ lập kế hoạch điều trị chính xác và phát hiện sớm.


















người
Đội ngũ tận tâm và được đào tạo:
- Hơn 30,000 cộng tác viên để Tạo dữ liệu, Ghi nhãn và Chất lượng
- Nhóm quản lý dự án được chứng nhận
- Nhóm phát triển sản phẩm có kinh nghiệm
- Nhóm Tìm nguồn & Giới thiệu Talent Pool

Quy trình xét duyệt
Đảm bảo hiệu quả quy trình cao nhất với:
- Quy trình cổng giai đoạn 6 Sigma mạnh mẽ
- Đội ngũ chuyên dụng gồm 6 đai đen Sigma - Chủ sở hữu quy trình chính & Tuân thủ chất lượng
- Cải tiến liên tục & Vòng lặp phản hồi

Nền tảng
Nền tảng được cấp bằng sáng chế cung cấp các lợi ích:
- Nền tảng end-to-end dựa trên web
- Chất lượng hoàn hảo
- TAT nhanh hơn
- Giao hàng liền mạch



