
Chú thích văn bản trong Machine Learning là gì?
Chú thích văn bản trong học máy đề cập đến việc thêm siêu dữ liệu hoặc nhãn vào dữ liệu văn bản thô để tạo bộ dữ liệu có cấu trúc nhằm đào tạo, đánh giá và cải thiện các mô hình học máy. Đây là một bước quan trọng trong các tác vụ xử lý ngôn ngữ tự nhiên (NLP), vì nó giúp thuật toán hiểu, diễn giải và đưa ra dự đoán dựa trên đầu vào văn bản.
Chú thích văn bản rất quan trọng vì nó giúp thu hẹp khoảng cách giữa dữ liệu văn bản phi cấu trúc và dữ liệu có cấu trúc, máy có thể đọc được. Điều này cho phép các mô hình học máy học và khái quát hóa các mẫu từ các ví dụ được chú thích.
Chú thích chất lượng cao rất quan trọng để xây dựng các mô hình chính xác và mạnh mẽ. Đây là lý do tại sao chú ý cẩn thận đến chi tiết, tính nhất quán và kiến thức chuyên môn về miền là điều cần thiết trong chú thích văn bản.
Các loại chú thích văn bản

Khi đào tạo các thuật toán NLP, điều cần thiết là phải có các bộ dữ liệu văn bản có chú thích lớn phù hợp với nhu cầu riêng của từng dự án. Vì vậy, đối với những nhà phát triển muốn tạo các bộ dữ liệu như vậy, đây là tổng quan đơn giản về năm loại chú thích văn bản phổ biến.

Chú thích cảm xúc
Chú thích tình cảm xác định cảm xúc, ý kiến hoặc thái độ cơ bản của văn bản. Người chú thích gắn nhãn các phân đoạn văn bản bằng các thẻ cảm xúc tích cực, tiêu cực hoặc trung tính. Phân tích tình cảm, một ứng dụng chính của loại chú thích này, được sử dụng rộng rãi trong giám sát phương tiện truyền thông xã hội, phân tích phản hồi của khách hàng và nghiên cứu thị trường.
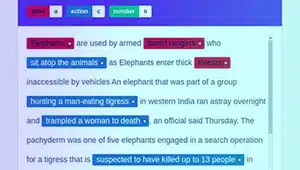
Chú thích ý định
Chú thích ý định nhằm mục đích nắm bắt mục đích hoặc mục tiêu đằng sau một văn bản nhất định. Trong loại chú thích này, người chú thích gán nhãn cho các đoạn văn bản thể hiện ý định cụ thể của người dùng, chẳng hạn như yêu cầu thông tin, yêu cầu điều gì đó hoặc thể hiện sở thích.
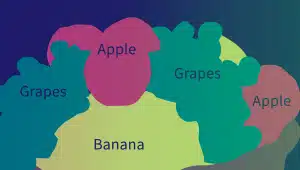
Chú thích ngữ nghĩa
Chú thích ngữ nghĩa xác định ý nghĩa và mối quan hệ giữa các từ, cụm từ và câu. Người chú thích sử dụng các kỹ thuật khác nhau, chẳng hạn như phân đoạn văn bản, phân tích tài liệu và trích xuất văn bản, để gắn nhãn và phân loại các thuộc tính ngữ nghĩa của các phần tử văn bản.

Chú thích thực thể
Chú thích thực thể rất quan trọng trong việc tạo bộ dữ liệu đào tạo chatbot và dữ liệu NLP khác. Nó liên quan đến việc tìm và dán nhãn các thực thể trong văn bản. Các loại chú thích thực thể bao gồm:

Chú thích ngôn ngữ
Chú thích ngôn ngữ liên quan đến các khía cạnh cấu trúc và ngữ pháp của ngôn ngữ. Nó bao gồm nhiều nhiệm vụ phụ khác nhau, chẳng hạn như gắn thẻ một phần của bài phát biểu, phân tích cú pháp và phân tích hình thái.

Bảo hiểm
Chú thích văn bản giúp các công ty bảo hiểm phân tích phản hồi của khách hàng, xử lý khiếu nại và phát hiện gian lận. Bằng cách sử dụng các mô hình AI được đào tạo trên bộ dữ liệu có chú thích, các công ty bảo hiểm có thể:

Ngân hàng
Chú thích văn bản tạo điều kiện cải thiện dịch vụ khách hàng, phát hiện gian lận và phân tích tài liệu trong ngân hàng. Các hệ thống AI được đào tạo trên dữ liệu được chú thích có thể:

Viễn thông
Chú thích văn bản cho phép các công ty viễn thông tăng cường hỗ trợ khách hàng, giám sát phương tiện truyền thông xã hội và quản lý các sự cố mạng. Các mô hình học máy được đào tạo trên bộ dữ liệu được chú thích có thể:
Làm thế nào để chú thích dữ liệu văn bản?
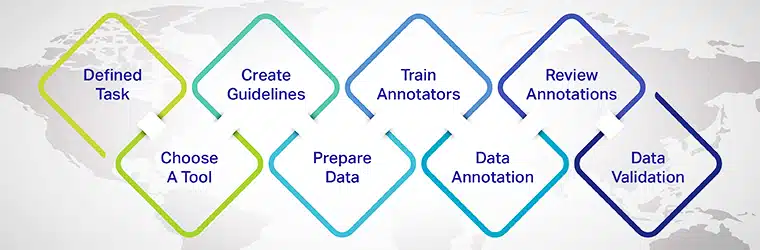
- Xác định nhiệm vụ chú thích: Xác định nhiệm vụ NLP cụ thể mà bạn muốn giải quyết, chẳng hạn như phân tích tình cảm, nhận dạng thực thể được đặt tên hoặc phân loại văn bản.
- Chọn một công cụ chú thích phù hợp: Chọn một công cụ hoặc nền tảng chú thích văn bản đáp ứng các yêu cầu dự án của bạn và hỗ trợ các loại chú thích mong muốn.
- Tạo hướng dẫn chú thích: Xây dựng hướng dẫn rõ ràng và nhất quán để người chú thích tuân theo, đảm bảo chú thích chính xác và chất lượng cao.
- Chọn và chuẩn bị dữ liệu: Thu thập mẫu dữ liệu văn bản thô đa dạng và mang tính đại diện để người chú thích làm việc.
- Đào tạo và đánh giá chú thích: Cung cấp đào tạo và phản hồi liên tục cho người chú thích, đảm bảo tính nhất quán và chất lượng trong quá trình chú thích.
- Chú thích dữ liệu: Người chú thích gắn nhãn văn bản theo các hướng dẫn và loại chú thích đã xác định.
- Xem lại và tinh chỉnh các chú thích: Thường xuyên xem xét và tinh chỉnh các chú thích, giải quyết mọi điểm không nhất quán hoặc lỗi và lặp đi lặp lại việc cải thiện tập dữ liệu.
- Tách tập dữ liệu: Chia dữ liệu được chú thích thành các tập huấn luyện, xác thực và kiểm tra để huấn luyện và đánh giá mô hình máy học.
Shaip có thể làm gì cho bạn?
Shaip cung cấp phù hợp giải pháp chú thích văn bản để cung cấp năng lượng cho các ứng dụng AI và máy học của bạn trong các ngành khác nhau. Với sự tập trung mạnh vào các chú thích chính xác và chất lượng cao, đội ngũ giàu kinh nghiệm của Shaip và nền tảng chú thích tiên tiến có thể xử lý dữ liệu văn bản đa dạng.
Cho dù đó là phân tích cảm xúc, nhận dạng thực thể được đặt tên hay phân loại văn bản, Shaip đều cung cấp các bộ dữ liệu tùy chỉnh để giúp nâng cao hiệu suất và khả năng hiểu ngôn ngữ của các mô hình AI của bạn.
Hãy tin tưởng Shaip để hợp lý hóa quy trình chú thích văn bản của bạn và đảm bảo hệ thống AI của bạn phát huy hết tiềm năng của chúng.

