Tất cả chúng tôi đã tương tác với các ứng dụng AI hội thoại như Alexa, Siri và Google Home. Những ứng dụng này đã làm cho cuộc sống hàng ngày của chúng ta trở nên dễ dàng và tốt đẹp hơn rất nhiều.
AI hội thoại đang thúc đẩy tương lai của công nghệ hiện đại và tạo điều kiện tăng cường giao tiếp giữa con người và máy móc. Khi thiết kế một trợ lý trò chuyện liền mạch hoạt động hiệu quả và chính xác, bạn cũng nên biết về nhiều thách thức phát triển mà bạn có thể gặp phải.
Ở đây, chúng ta sẽ nói về:
- Các thách thức dữ liệu phổ biến khác nhau
- Những điều này ảnh hưởng đến người tiêu dùng như thế nào?
- Những cách tốt nhất để vượt qua những thách thức này và hơn thế nữa.
Những thách thức về dữ liệu phổ biến trong AI hội thoại
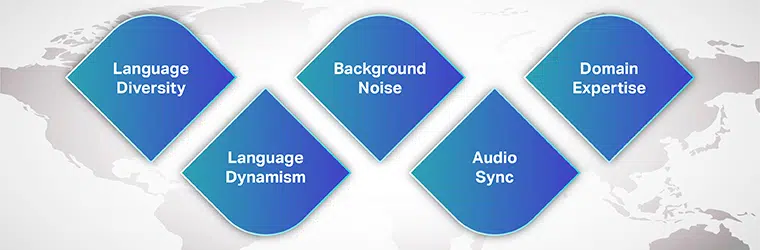
Dựa trên kinh nghiệm làm việc với các khách hàng hàng đầu và các dự án phức tạp, chúng tôi đã tổng hợp danh sách các thách thức phổ biến nhất đối với dữ liệu AI đàm thoại đối với bạn.
Đa dạng ngôn ngữ
Việc xây dựng một trợ lý trò chuyện dựa trên AI có thể đáp ứng cho sự đa dạng của các ngôn ngữ là một thách thức lớn.
Có khoảng 1.35 tỷ người người nói tiếng Anh như ngôn ngữ thứ hai hoặc ngôn ngữ mẹ đẻ. Điều này có nghĩa là ít hơn 20% dân số thế giới nói tiếng Anh, phần còn lại của dân số nói chuyện bằng các ngôn ngữ khác ngoài tiếng Anh. Vì vậy, nếu bạn đang làm trợ lý trò chuyện đàm thoại, bạn cũng nên xem xét sự đa dạng của các yếu tố ngôn ngữ.
Chủ nghĩa động ngôn ngữ
Bất kỳ ngôn ngữ nào cũng có tính năng động và việc nắm bắt tính năng động của nó cũng như đào tạo thuật toán học máy dựa trên AI không phải là điều dễ dàng. Phương ngữ, cách phát âm, tiếng lóng và sắc thái có thể ảnh hưởng đến mức độ thành thạo của mô hình AI.
Tuy nhiên, thách thức lớn nhất đối với một ứng dụng dựa trên AI là giải mã chính xác yếu tố con người trong đầu vào ngôn ngữ. Con người mang lại cảm giác và cảm xúc trong cuộc xung đột, khiến công cụ AI khó hiểu và phản ứng.
Tiếng ồn nền
Tiếng ồn xung quanh có thể có trong các cuộc hội thoại đồng thời hoặc các âm thanh chồng chéo khác.
Loại bỏ bộ sưu tập âm thanh của bạn để loại bỏ các tạp âm nền gây nhiễu, chẳng hạn như chuông cửa, chó sủa hoặc trẻ em nói chuyện trong nền là rất quan trọng cho sự thành công của ứng dụng.
Bên cạnh đó, ngày nay các ứng dụng AI phải đối phó với các trợ lý giọng nói cạnh tranh có mặt trên cùng một cơ sở. Trợ lý giọng nói sẽ khó phân biệt giữa lệnh thoại của con người và các trợ lý giọng nói khác khi điều này xảy ra.
Đồng bộ hóa âm thanh
Khi trích xuất dữ liệu từ một cuộc trò chuyện qua điện thoại để huấn luyện trợ lý ảo, có thể có người gọi và người đại diện ở hai đường dây khác nhau. Điều quan trọng là phải đồng bộ hóa âm thanh từ cả hai phía và ghi lại các cuộc trò chuyện mà không cần tham chiếu chéo mọi tệp.
Thiếu dữ liệu dành riêng cho miền
Một ứng dụng dựa trên AI cũng phải xử lý ngôn ngữ dành riêng cho miền. Mặc dù trợ lý giọng nói đang thể hiện sự hứa hẹn đặc biệt trong xử lý ngôn ngữ tự nhiên, nó vẫn chưa chứng minh được sự thống trị của họ đối với ngôn ngữ dành riêng cho ngành. Ví dụ: thường sẽ không cung cấp câu trả lời cho các câu hỏi theo miền cụ thể về các ngành ô tô hoặc tài chính.
Những thách thức này ảnh hưởng đến người tiêu dùng như thế nào?
Trợ lý trò chuyện AI hội thoại có thể tương tự như tìm kiếm dựa trên văn bản. Nhưng, một sự khác biệt cơ bản giữa hai điều này tồn tại. Trong hỗ trợ tìm kiếm dựa trên văn bản, ứng dụng cung cấp danh sách các kết quả tìm kiếm có liên quan mà người dùng có thể chọn, mang lại cho người dùng sự linh hoạt rất cần thiết trong việc chọn một trong các tùy chọn.
Tuy nhiên, trong AI đàm thoại, người dùng thường không có nhiều hơn một tùy chọn và họ cũng mong đợi ứng dụng cung cấp kết quả tốt nhất.
Nếu công cụ trí tuệ nhân tạo đi kèm với sai lệch dữ liệu, kết quả chắc chắn sẽ không chính xác hoặc đáng tin cậy. Kết quả có thể bị ảnh hưởng bởi mức độ phổ biến chứ không phải do yêu cầu của người dùng, làm cho kết quả trở nên thừa.
Giải pháp: Vượt qua những thách thức trong giai đoạn thu thập dữ liệu
Bước đầu tiên để chống lại sự thiên lệch trong đào tạo là nhận thức và chấp nhận. Khi bạn biết rằng tập dữ liệu của mình có thể có nhiều sai lệch, bạn nhất định phải thực hiện hành động sửa chữa.
Bước tiếp theo sẽ là chủ động cung cấp các biện pháp kiểm soát để người dùng thay đổi cài đặt nhằm bù đắp sự thiên vị một cách trực tiếp. Hoặc, phản hồi có thể được lặp lại vào hệ thống để giảm thiểu các vấn đề thiên vị một cách chủ động.
Giảm thiểu tiếng ồn xung quanh, các cuộc trò chuyện đồng thời và xử lý nhiều người yêu cầu các kỹ thuật nhận dạng giọng nói nâng cao. Hệ thống cũng cần được đào tạo để hiểu cuộc hội thoại theo ngữ cảnh và các từ hoặc cụm từ.
Khả năng xác định giọng nói không phải của con người cũng có thể được nâng cao khi hệ thống được giới thiệu để giải quyết những người hoặc giọng nói không được đăng ký.
Khi nói đến sự đa dạng trong ngôn ngữ, giải pháp nằm ở việc tăng số lượng bộ dữ liệu ngôn ngữ được sử dụng để đào tạo mô hình. Vì vậy, khi các doanh nghiệp phát triển số lượng hệ thống để phục vụ cho các thị trường ngôn ngữ rộng lớn, thì sự đa dạng ngôn ngữ có thể đạt được một cách liền mạch.
Lợi ích của việc làm việc với các nhà cung cấp bên ngoài
Có một số lợi ích khi làm việc với các nhà cung cấp bên ngoài vì họ giúp giảm thiểu một số thách thức trong việc thu thập dữ liệu đàm thoại.
Làm việc với các nhà cung cấp bên thứ ba có kinh nghiệm mang lại hiệu quả chi phí và độ tin cậy cao hơn. Nó là hiệu quả về chi phí nhận bộ dữ liệu chất lượng từ các nhà cung cấp đáng tin cậy thay vì thu thập dữ liệu từ bộ dữ liệu đào tạo AI đàm thoại nguồn mở.
Mặc dù sai lệch nhất định phải có trong mọi tập dữ liệu, nhưng với một nhà cung cấp bên ngoài, bạn có thể giảm chi phí liên quan đến việc làm lại hoặc đào tạo lại mô hình của mình vì sự khác biệt về dữ liệu và quá nhiều thành kiến về ngôn ngữ.
Một nhà cung cấp có kinh nghiệm cũng sẽ giúp bạn tiết kiệm thời gian thu thập dữ liệu và chú thích chính xác. Một nhà cung cấp bên ngoài sẽ có kiến thức chuyên môn về ngôn ngữ bắt buộc để phát triển các mô hình AI có thể mở ra thị trường mới hơn cho doanh nghiệp của bạn.
Nhà cung cấp có thể cung cấp bộ dữ liệu chất lượng cao, có thể tùy chỉnh phù hợp với sở thích và yêu cầu mô hình của bạn. Không phải tất cả các giải pháp thu thập và chú thích dữ liệu đóng gói sẵn đều có thể có lợi cho bạn khi xem xét dịch vụ khách hàng nâng cao, tỷ lệ chuyển đổi cao hơn và giảm chi phí kinh doanh.
Chúng tôi có Dữ liệu đàm thoại mà mô hình AI của bạn cần.
Là một nhà cung cấp đáng tin cậy và có kinh nghiệm, Shaip có một bộ sưu tập đồ sộ gồm bộ dữ liệu AI đàm thoại cho tất cả các loại mô hình học máy. Bên cạnh đó, chúng tôi cũng cung cấp dữ liệu hội thoại được điều chỉnh hoàn toàn bằng một số ngôn ngữ, phương ngữ và tiếng bản địa. Nếu bạn muốn phát triển một ứng dụng hỗ trợ trò chuyện dựa trên AI đáng tin cậy và chính xác, chúng tôi có tất cả các công cụ có thể giúp dự án của bạn thành công.